People working in IT are familiar with the term DTAP, which is a shorthand for Development, Test, Acceptance, and Production. In one way or another, this has been a staple of IT changes in organisations for a long time, even the agile methodologies of today work with the idea — though on a more granular scale. The main goal is to manage risks, as we all should know by now that IT is rather fundamentally brittle and a lot can go wrong. Even general management — being interested in the combination of (advantageous) change and risk — will be aware. But what not everybody is aware of is that the situation is a lot more complex, and not everybody is aware of what that means for, for instance, things like risk, security, or continuity requirements.
Before we go on, we will remove the Acceptance part of DTAP from this story (we’ll still call it DTAP, just for historical purposes). The DTAP structure with Acceptance stems from a time where IT and ‘Business’ were more separated beasts. Development was one form or another of programming, Testing meant ‘technical’ tests (by the techies). After that, it was the first time that the ‘users’ would get involved in the delivery pipeline, they would work with a new version to see if there were problems. And when the users accepted the new version it would go into Production.
But the idea of IT being automation that is just there to support ‘human behaviour’ is rather outdated. Most IT exists to support other IT. Some businesses’ ‘production’ behaviour consists almost entirely of machine logic. Sure, there is in the end a human intention to be realised, but these may be ‘far away’ from what we are changing. Furthermore, there are often other types of testing depending on the actual situation, such as a pre-production environment — formal ‘testing’ being done with synthetic data because of privacy guidelines, and pre-production being done with ‘test’ machine logic but done with ‘production’ data. Is that ‘production’ or is that ‘test’? We’ll see below.
We keep Development, because even if people often do not realise it, configuring a new system or version is ‘development’, There is more to development than programming and coding. In fact, IT ‘development’ should cover every technical change in the landscape. So, a better name might be Change, Test, Production (CTP), but we’re probably stuck with DTAP.
DTAP has three phases:
- Change (development)
- Test (these can be multiple in a series, if we fail we go back to the previous phase)
- Production
If this was all there is, the IT-delivery world would be simple. But, as always in IT, in the real world, if hardly ever is.
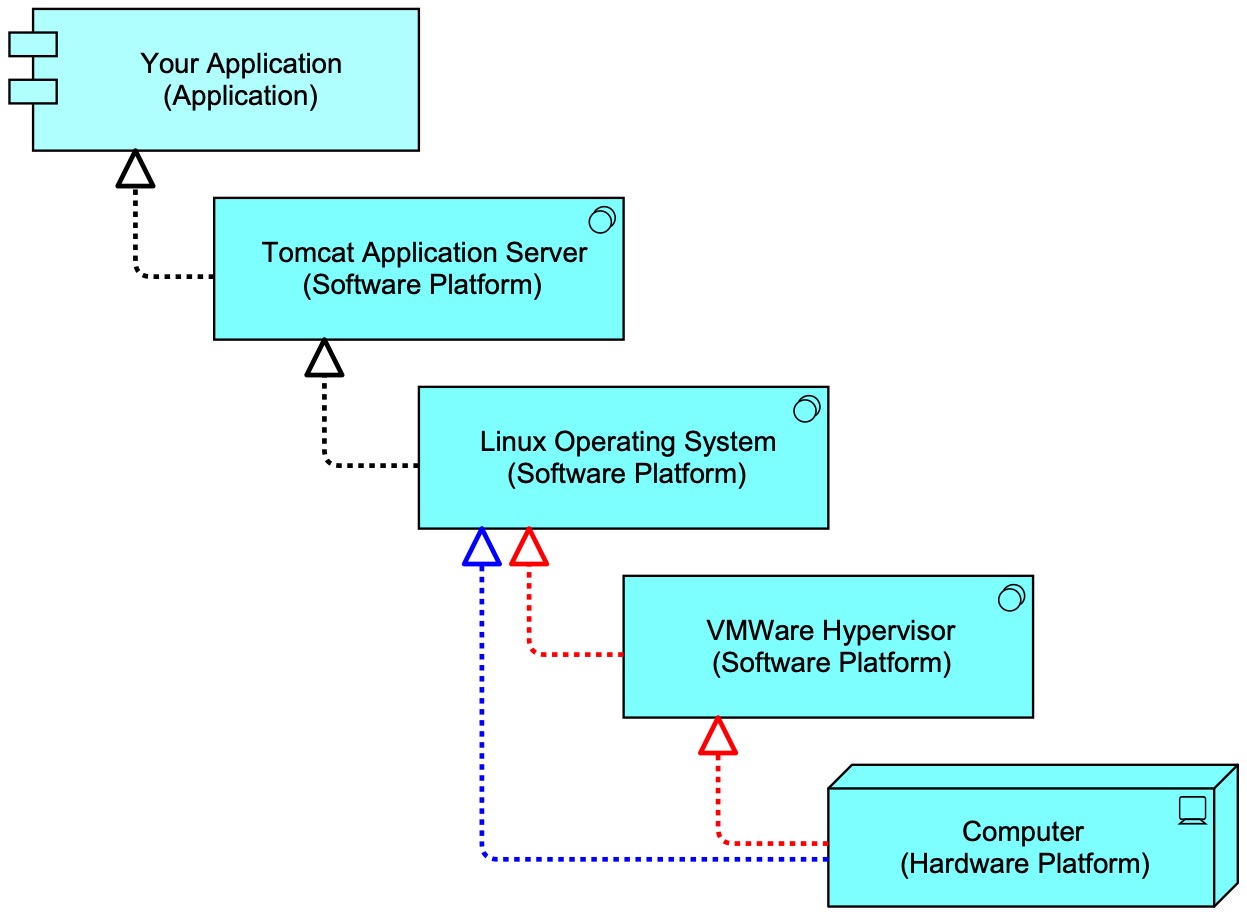
Let’s start with a simple example. You are developing a Java application that runs on a Tomcat application server. This means, Tomcat acts as a platform. People often have trouble deciding on what a ‘platform’ is, but for me the definition is very simple (for once 😀):
In IT, a Platform is an IT system on which we can Deploy other IT
Me. Now.
So, as your application is deployed (installed) on Tomcat, Tomcat is the platform for your application. But wait. Tomcat needs to be installed (deployed) as well. So, the platform for Tomcat is an Operating System, such as Linux or Windows. Ah, yes. But that Operating System also must be installed on either physical hardware (a physical computer) or virtualised hardware. In the first case, the physical computer is the hardware platform on which the Operating System is deployed. In the latter case, there is another layer: the hypervisor, like VMWare or Parallels. In that situation, the Operating System is deployed on the hypervisor, which in turn is deployed on the physical computer. In a a diagram (ArchiMate — using Mastering ArchiMate colours where blue is used for active elements and green for passive elements)

It’s Platforms All The Way Down.
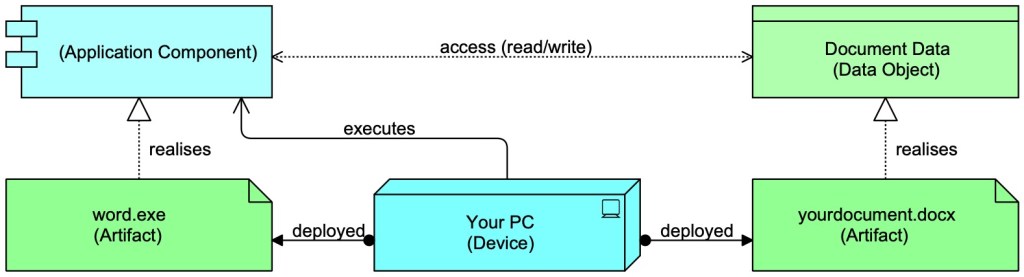
Aside: we can deploy programs (executable logic) and data. In reality, deploying is always deployment of data, it is just that some data is executable by a platform below. In ArchiMate this is modelled by showing such ‘executable data’ as ‘bits’ as well (Artefact = ‘bits’) and show it realises a machine logic ‘actor’ that can have (logical) ‘behaviour’ that can act on other data, e.g. when you use Word to edit a document:
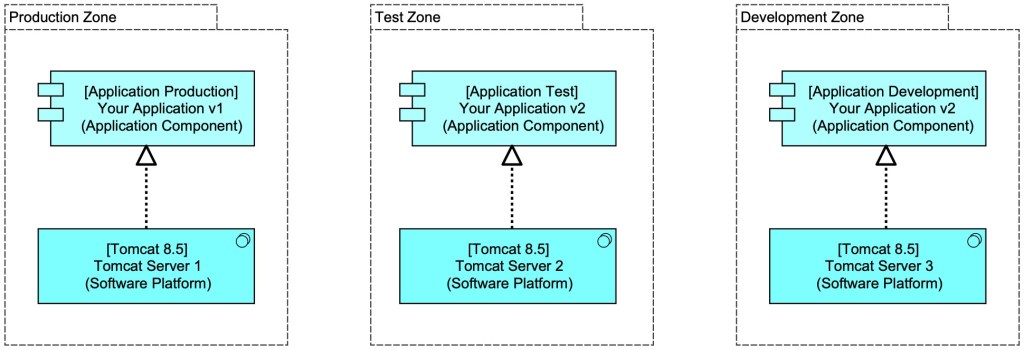
You develop your application, an application that runs in the Tomcat version 8.5 Server. Your application version 1 is running in production and you develop versions 2. This new version needs to be tested before it goes into production. If you want to put your version 2 in production, you need to develop and test it on the same platform as it will be running on. That might be depicted like this:
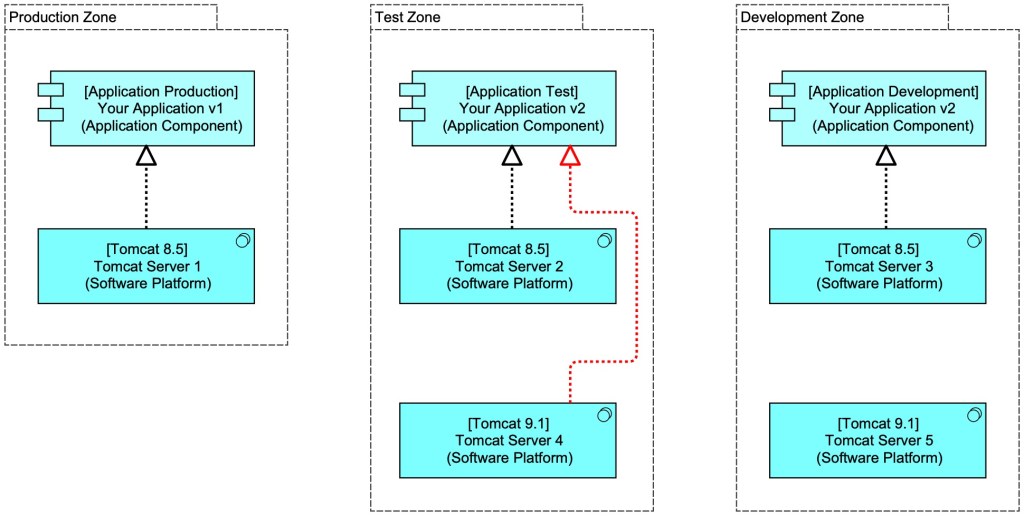
So far, so simple. But what happens when a new version of Tomcat will be used, say Tomcat 9.1? This too needs to be ‘developed’ (e.g. create security baselines, logging, monitoring, etc. for it and so make sure Tomcat is deployed in a controlled state) and tested. It turns out, this too has a DTAP. And as you are ‘developing’ and deploying your, application, you might also want to test your new version of the platform by deploying a test of your application. This could be depicted like this:
You might feel what is going to happen now: this is true for all platforms. Your application has DTAP, but so do all the platforms in the stack of platforms below. Here is that application you are maintaining (called ‘App’) in your organisation with two platform layers underneath:

And in reality, layers sometimes depend on multiple platform in parallel underneath. E.g. your Java application deployed in a Tomcat application server depends on a Tomcat and a Java runtime, and these ‘parallel’ platform dependencies may even depend again on one another, creating more of a web than a stack. And you might have deployed all kinds of libraries that might have seen very little life cycle management over the years. Log4j, anyone? (If this is the first time you start to realise how many dependencies there are, you might become a bit dizzy — this is normal. Breathe in. Breathe out.) But then again, this is what we have been doing for over half a century, fighting the complexity and brittleness that comes from that complexity and machine logic’s fundamental properties
How many layers are there in serious landscapes? Large organisations will have 6 layers easily. E.g.:
- Hardware platform
- Hypervisor
- Operating System
- Runtime(s) — often multiple in parallel, sometimes stacked even (meaning we get more than 6)
- Data Science Platform
- Models
Yes, those models too. They are logic created by data scientists. But here too, models will be developed, tested, and then put in production. Maybe someone should tell the data scientist that they are just a specialist type of programmer. Just like you had to tell those portfolio analysts and quants that their spreadsheets were applications running in the Excel platform.
And all those platforms often offer behavioural ‘richness’ (like being able to use other platforms), that programmers really like but that in security circles is called an ‘attack surface’ (i.e. your web site suffering from code injection by the baddie that is executed in your environment (oops) — the recent log4j scare was such a vulnerability).
Which brings us to some interesting complexity I’ve seen people struggle with regarding platforms: stacked information security and stacked business continuity. We’ll take the former as an example.
Stacked Information Security
In serious environment, your application will have set for itself requirements regarding information security and business continuity. For information security, these generally are the ‘CIA’-ratings:
- Confidentiality — how important is it to keep the data confidential?
- Integrity — how important is it to keep the data uncorrupted?
- Availability — how long may the application be unavailable?
and they are documented as some sort of rating, say a number from 0 to 3. An application that has confidentiality 3 may contain very sensitive information, say health records. One with confidentiality 2 may be sensitive, but slightly less so, say your address. And with confidentiality 0, we are talking about public information. Availability 3 may mean: this application should be perfectly available, 100% of the time (e.g. a trading system’s outage may cost us millions if we cannot trade when we have to). Such a high Availability rating may thus lead to some sort of clustered, high-available, solution. Availability 0 might mean: we accept it if the application is unavailable for a maximum of one week. Availability 2 could be: maximum one hour unavailable. A database with addresses to distribute marketing materials to may have an integrity rating of 1: not that much harm comes from a flyer being distributed to a wrong address. The addresses of patients where health data is sent to may again be 3. Etc.
It is obvious that these ratings have their effect on underlying platforms, they form a requirement of sort. Your application may be secure in handling the data (e.g. have proper identity and access management to the application), but if the database platform used by it is wide open, that confidentiality setup on a higher layer may mean little.
So, the further we go down, the higher our ratings have to be? It is not that simple. Here are some examples:
- An application that requires high availability but runs on a platform that has lower availability might instead run on a load-balanced cluster of that lower rated underlying platform, the total setup again having a higher availability. The lower platform itself does not need to be designed with higher availability, we can work around its deficiency;
- An application stores confidential data in an object storage platform, say MinIO. If someone wants to use MinIO directly (instead of the application) to get at the data, they cannot, because the MinIO has been well designed in terms of access management. Only applications that are allowed can get access to only their own data. But what if the configuration of MinIO itself has low integrity? What if someone could easily remove the safeguards with which MinIO has been configured? If the MinIO configuration has low integrity, the confidentiality of what is stored inside is compromised. On the other hand, there is no need for the MinIO configuration itself to be confidential. If someone can see but not change the identity and access measures, the data inside is still safe (we do not rely on security through obscurity). Surprisingly, high confidentiality of the higher layer requires a high integrity (and not per sé high confidentially) of the lower. And that integrity at lower layer might again require a high confidentiality in some other part of your landscape, e.g. if your confidentiality rests on a public/private key pair you want to keep that private key very confidential;
- If my database platform has a confidentiality rating of 2 and I want to store data with a confidentiality rating of 3, I could let my application encrypt my data before storing it, thus working around the limitation of the database platform. No need to make the database platform handle rating 3. Or, I could use a database platform that supports native encryption in such a way that while the application can access it, the database operators cannot;
- A very old example: The TCP/IP network stack on which all computer networking is built these days has IP (the ‘Internet Protocol’) at its lowest layer, on top of that one has the choice of TCP or UDP. TCP is a protocol with guaranteed delivery of each packet of data, but UDP is a protocol without guaranteed delivery of each packet (but therefore with minimal overhead and fast). NFS is a network share protocol on top of UDP. A network share must of course have very high integrity, or your files get corrupted. NFS has to create the integrity of the data itself, it cannot rely on UDP. SMB, on the other hand is another file sharing protocol which can rely on the integrity of the transport of TCP below.
All of this technical stuff means that when we discuss the health of a design for a platform there are in fact at least three sets of CIA-ratings in play, and not just one:
- The CIA-ratings of the platform(s) that support our platform.
- The CIA ratings of the platform itself, e.g. how confidential is the configuration of the platform?
- The CIA-ratings our platform can support without extra measures.
The first are of cours apart of the design of those supporting platforms, we don’t have to create these, we use them as a given and we have to work around their limitations if the ratings are too low. But our design will have to contain both the second and the third.
So that means that if you make a design of an IT platform implementation in your landscape, you should have at least two information security ratings, not one.: one for your platform itself and one for what your platform offers to what is deployed on it..
Comparable complexity exists for business continuity (reacting to business not-as-usual), stuff like “if there is a disaster, how much data may get lost?” (RPO) or “if there is a disaster, how much time may pass before we are up and running again?” (RTO).
Takeaway: Most IT is there to support other IT. Much of IT is platforms: IT supporting other IT in sometimes amazingly complex dependency relations, and even small mistakes may bring the entire edifice down (and your application with it). So please pay attention to those parts: it is about more than just that primary function you have in mind, and the web of dependencies is also a web of information security relations, which we cannot handle simply by creating a single information security (Confidentiality, Integrity, Availability) rating for each part. You need at least two. Sorry.

There is even more complexity. You have chosen to model ‘platforms’ of some type as a generic concept. In reality platforms lot’s of the time are specific for an application, as being a grouping and realization of a set of platforms. In that way forming a composed platform for which I think one should identify such a specific, composed platform.
LikeLike
Indeed. Sometimes we have a combination of applications and platform. I call these ‘Complex Application Stacks’. A good example would be SAS which has a runtime where code (in SAS-specific language) is deployed, but also applications, e.g. for management of the ‘stack’.
But, hey, I could have added much more complexity (reality) but that would make the story more complex as well and hard to follow for people for who this is not there day to day subject. For many, this will be confusing enough as it is.
LikeLike