For reasons that will remain hidden, we resume writing about Generative AI/LLM after a hiatus of 15 months (that one from October 2025, and the one from June 2025, don’t really count as serious pieces). Today, the first of two articles about “coding with Large ‘Language’ Models”, as coding with LLMs is positioned as the ‘killer app‘ for LLMs.
We interrupt this program for a short digression on Anthropic’s recently released blog post When AI builds itself.
Did Anthropic perchance hire Google marketeers?
Anthropic’s blog post is a masterclass in suggestive writing. The caveats are there, but hidden or sandwiched between more hyperbolic statements. A sentence ‘we might be wrong’ is there, but what role has it as a single sentence in thousands of words of text assuming that they are not wrong? The benchmarks are suspect (a 50% or even 80% success rate on a coding task compared to a human is effectively completely useless in full-agentic (no human in the loop) coding. Is checking in 8 times as many lines of code per day really a good thing? What if every day you are replacing what wasn’t OK the day before? What if LLMs edit in a way that Lines of Code becomes less trustworthy a measure as it is already? All in all, it reminds me of Google’s deceptive talk about its ‘Willow’ QM computing chip.
By the way, on that “Is checking in 8 times as many lines of code per day really a good thing?”: A lot of my LLM-based checkins have been like that, and frankly, I have increased my number of checkins just to be able to backtrack if Claude Code has gotten lost. Even with all the work I did without intermediary checkins, I committed 7 times as much change than I ended up with in terms of lines of code…. So, ‘8’ as an estimate not so much of increased productivity, but of increased overhead does sound about right…
We will return to this if I get around to writing the in-depth of ‘coding with Claude’ later.
And while we’re at it. This is a long and winding piece (I am really having some trouble on this front, apologies), so let’s provide:
TL;DR — It doesn’t look like LLM-coding is going to be affordable
(let alone for “AI to build itself”)
I have been doing some experimenting. The experiment is: “How good is Claude Code anyway?”. That experiment is still running and Claude Code has by now created around 40k lines of code and a working (though incomplete) application. I hope to report on that experience in a short while (but it is a much more difficult write-up). In the meantime, I experienced the cost issue and it led to a short research project, which led to a number of interesting observations and conclusions:
- Let’s start with an important observation: Thanks to the combination of Claude Code and my own (rusty, but solid enough) programming background, I have been able to let Claude Code create this application (unfinished as of now, but functional) that I would otherwise not have been able to create in such a short amount of time, which — given time and energy — would have meant: ‘not at all’. For an experienced programmer, the initial experience is extremely impressive as an experienced programmer knows how much understanding by themselves normally goes in to creating such code;
- But… LLM-coding isn’t economically viable for most uses. It is viable now because the subscriptions are heavily subsidised. But if you use the $100 a month Claude Max plan, and you would use it to the weekly limit by going full ‘agentic coding’ (so almost no human in the loop) you would use an amount of tokens that would cost you more than $1000 at API-pricing. Anthropic seems to be busy (Opus 4.7, 4.8) to stop that bleeding, and even if that succeeds without a loss of quality, it does signal an end of substantial improvements (i.e. the end of an S-curve);
- And… while simple conversations with either budget or frontier models have become indeed ‘too cheap to meter’, the serious uses (like coding, complex reasoning) that require the recursive/indirection/tool-using/’thinking’ (not) models have exploded so much in token use that these uses have become very expensive. A single task by a top recursive model at high effort is estimated to cost around $75 at API-rates. I have seen a single query use one million tokens, which would mean max $25 at API-rates;
- So… the economic model that is being presented to the world seems based on the combination of the value of the tasks that require a maximum amount of brute force to approximate good results on anything complex, while hiding the cost or talking about ‘too cheap to meter’;
- Hence: enjoy the music for as long as this ship hasn’t sunk, and prepare a good life raft.
Here is a part of a screen shot of the application I am building (and having some fun with). It’s a real application which may support me in creating diagrams I need (so it’s a combination of data and graphics). The goal has been to investigate ‘coding with an LLM’, the thing I am building is just an example I thought I could use because I am somewhat experienced on the subject:
Let’s start with an important observation: Thanks to the combination of Claude Code and my own (rusty, but solid enough) programming background, I have been able to let Claude Code create an application (unfinished as of now, but functional) that I would otherwise not have been able to create in such a short amount of time, which — given time and energy — would have meant: ‘not at all’. But there is a catch. A few even. I will report later on the technical issues and an answer to the question: “To what extent does Claude Code actually ‘code’?”. Today it is simply the economics that struck me.
I built up my ‘vibe coding’ (I really dislike that term, there is little ‘vibe’ about coding with or without an LLM) experiment over — by now — 4 months (not full time, note). I started with a very small project to get a feel of LLM-coding, finally settled on Claude Code using Opus 4.6 on medium effort setting. If I used a higher setting it tended to get lost in the woods more often. Less, and the results were poor (more on managing the quality of the code in that later post). After a while on my final more serious project (the last two months) the results of ‘medium effort’ got worse, so I switched to ‘high’, returning to approximately the same quality.
Managing cost was also part of the experience. First, I took out a $20/month subscription. I quickly ran into usage limits. You have a limit that resets every 5 hours and one that resets every week, you can go beyond the limit by buying tokens at API-pricing. So, I tried adding some extra funds. And I noticed that the use of purchased tokens at API-cost was obviously much more expensive that staying within the usage limits. When I was still on the $20/month plan, and I bought some extra tokens to get some job finished, within a few days I had bought about $80 of tokens. At that point it became clear to me that paying $100/month was a much, much better deal than using the cheapest option and adding funds at API-cost level when needed.
I had already been looking at cost, e.g. training versus inference (generating results by Generative AI) a while back, concluding that not training, but inference/generation is what drives the cost. Having concluded that, I now started to look into the cost of LLM-use to perform a task. And I — disclosure — actually used a few LLM-chatbots (Gemini, Claude) to help me in this research. Now, before you stop reading because you are convinced these LLMs are too unreliable, they really are pretty decent search engines, even if they make mistakes on content they produce themselves. After all, they have ingested all those ArXiv articles and what a classic web search based on page-rank would not have been able to do, LLMs can: they find you information based on its actual content. People using LLMs in office setting will corroborate this.
The first answers I got were the standard quick & dirty answers, like Sam Altman’s famous: inference having become ‘too cheap to meter’. Such statements turned out to be true but also misleading/incomplete, very much so, as you will see. At the end of the day, the price ‘per token’ is not what is relevant for users, it is how much you pay for getting a ‘resolution’, or a ‘task finished’. And we already knew that while the results have improved, the amount of tokens had skyrocketed, especially with the indirect/recursive (‘thinking’ models. [Aside: calling them ‘thinking models’ is extremely misleading. They do nothing of the kind. What they do is above all a massive amount of invisible recursion, indirection, and trial and error. Like an LLM creating 20 or a 100 approaches behind the scenes, doing that time and again, use some additional tools (like first generate a python script, then run that script — having to run it multiple times until there are no obvious bugs in that script), maybe even test it a few times, and then use the output of that as more input for the LLM. And so on. A lot of indirection and recursion, a lot of ‘trial and error’, everything almost invisible to the user.] So, I investigated that trend, starting with “How much tokens did the average query use between Q1 2023 and now?” so I could combine falling per-token cost with rising amount of tokens used. After a few tries, I started a new conversation with a more focused start prompt.
It is important to keep in mind that people do not want the result of a single query, that is only true in the most simple tasks. In reality, they often make multiple queries and there is a back and forth, before they accept the result. So, you also need to estimate how many queries on average it takes to get to a resolution.
And then there are all those tokens you do not see. There are tokens that aren’t part of billing, there are ‘dark tokens’, and with the mis-labeled ‘thinking’ models there is a massive load of indirection/recursion and an incredible amount of ‘trial and error’ in the background going on, things you do not see as input or output, but all using a shitload of tokens. We know that these ‘recursive’ models use amounts of tokens that dwarf what you as a user see as result.
These are also tokens that you do not see, but they are nonetheless billed to you at visible output (generated) token cost. To get an idea of cost, Opus 4.6 when you pay per-token charges you $5/million tokens input (the data you give it, e.g. what it extracts from your code base on every query and what it reads in the background), and $25/million tokens generated data (including that generation that is in those ‘recursive efforts’ in the background.
Anyway, almost all of this is a lot of estimation. There is precious little hard data. This post is the result based on whatever best and reasonable estimates I could come up with, which in part is hard data: my own experience so far.
To show the development of use-cost, I’ve come up with a little framework:
The first element is how to measure per-token cost. We will look at subscriptions below, but the standard we follow is how ‘API per-token’ costs have developed over time. This is the best estimate we have of real token cost, but it is fragile, because as long as the vendors do not open up about this we must make an assumption. Do they make a profit at API-pricing? Or is that use still actually loss-making and subsidised? Either is a believable scenario at this time. And weird things have happened to API-pricing (see below). But we do not have better. Today, a top model like Claude Opus 4.6 costs you $5 for every million token you put in (your code, your documents, your queries) and $25 for every million tokens that Claude Opus 4.6 generates. That sounds very cheap, but here the ‘stuff you do not see’ is going to play a role.
Then there are two kinds of tasks people use LLMs for. One is fault-tolerant: it isn’t extremely important that the result is very accurate, this is the use that may be compared to ‘cheap clothes’: not very good, but cheap (an example taken from the start of the Industrial Revolution when physical labour started to get automated in factories, something the Digital Revolution is now doing to some mental labour). Such requests will also be followed up with far fewer follow-up queries and replies, people simply accept what the LLM produces.
But there are areas where accuracy is extremely important: coding is an example. IT is extremely brittle. One small error can bring the airline down, after all. Such quests are therefore fault-intolerant, we need correct results. Other examples may be health, finance, etc. where small errors may have large negative consequences. The amount of accuracy is especially an issue you have with Generative AI. It is large-scale statistical estimation, so inaccuracy is an unavoidable risk.
In other words, there is not a single kind of ‘quest’ (a series of queries until resolution, i.e. a task) that people use LLMs for, it ranges from a quick question where high accuracy is not really that important to tasks that are extremely dependent on actually correct results. The (‘fast’) budget models are quick, and indeed ‘too cheap to meter’ for simple stuff, and as long as the resolution is well represented in the data, and as long as the issue is not too complicated, the models do a ‘good enough’ job for many. Let these budget models loose on anything serious, however, and their results are by definition unreliable and thus often poor. But frontier models and — especially — recursive (‘thinking’ — ugh) models can be applied to such more complex tasks, and more difficult requests.
Today’s frontier models, such as Claude Opus 4.x or GPT 5.x do much more estimation, have internal parallelism, work with larger token dictionaries, have more dimensions, and the questions they are used for are generally larger. Expect several thousands of tokens on average for a quest, and more calculations per token.
And then there are the (frontier) — repeat ad nauseam: misnamed — ‘thinking’ models. These models may use tens of thousands, even millions of tokens, on a single quest depending on the task at hand. I actually ran into something like that with Claude 4.6 Opus in my coding experiment which — on a code base grown to about 36000 lines — used ~1 million tokens on a single (quite simple, for a human) query. That’s $25 for a single query of a single task when billed at API-prices. An outlier, certainly, but not that much of an outlier (a few hundred thousand tokens for a single query I saw much more often).
There is a third aspect that is easy to overlook. Because there is a difference between ‘correct‘ results and ‘accepted‘ (as correct) results. There is a difference between ‘when am I satisfied with the result’ versus ‘is the result actually correct’ In some cases it is much easier to verify correctness (think math, partly code — e.g. “does it compile?”, “does it run?”) than in others, like the research I have done for this article. At some point during my research I got results where my ‘common sense’ told me: “This cannot be right.”. And by digging in I found out that the LLM had taken quite a weird shortcut. For which it — of course — apologised when I pointed that out. [Aside: apologies by LLMs are as irritating as apologies with the help of LLMs.]
It is important to note that we are looking at a moving target here. When ChatGPT arrived late 2022, the average query may have been around 200 tokens, the reply (inference) around 400. But the things we do with ‘frontier’ models today was completely impossible with the frontier models of 3 years ago. What was ‘frontier’ capability then is ‘budget’ now. So, we look not so much at the history of ‘cost per token‘, but the history of ‘cost per task‘, where — as LLM systems have grown (with lost of scaling and engineering and little fundamental improvement) — the most difficult quests have become more complex too. Our use has grown with the growth of brute force these systems can bring to the table. And that leads to the question I was really interested in: How much more expensive has our use become? And how much do we actually pay?
I ended up plotting the estimated history of ‘cost per task’ for the following categories in my framework:
- Budget conversation (fault-tolerant). Reliability isn’t extremely important, it’s simple stuff that is hard to get wrong, using a budget model is fine.
- Frontier conversation (fault tolerant). Using a top model for a back and forth, but the result doesn’t need to be perfect.
The others are all based on using the recursive/indirect models. The vendors call these ‘thinking’ models but as said above that is utter bullshit. I will use ‘recursive models’ as a shorthand.
- Complex reasoning — correct. A conversation about a complex issue and the reasoning is correct. How much does that cost?
- Complex reasoning — accepted. A conversation about a complex issue and the reasoning is accepted by you, but it isn’t necessarily correct. How much does that cost?
- Simple coding — correct. You ask a model to create a simple script, maybe a few hundred lines. Or you ask it to change something in such a script. You get a correct result.
- Simple coding — accepted. You accept the result, but there are issues you haven’t noticed. Again, the gap between these two in coding is much smaller than for complex reasoning, for the simple reason that it is easier to find out if a result is incorrect with something like code.
- Complex multi-file coding — correct. You are asking for a substantial change in a larger code base. E.g., my experiment is about a code base now grown to 40k lines of code (mostly C++). We’re talking about single change that touches multiple files in the code base. Doing this without the code turning into a mess in my experience requires the most powerful models such as Claude Opus 4.6 in extended (recursive) mode. Note that this quest may take several back-and-forths between you and the model, possibly with some testing in between.
- Complex multi-file coding — accepted. You accept the change, but actually it isn’t correct (and you find out later). Actually my experience is that a lot of the time I am (together with Claude Code) busy debugging the code Claude Code has generated. Say, it doesn’t work as planned, Claude convincingly says it has found the problem. It creates a fix. Which doesn’t work, etc. Note: the result is still far more than I ever could have done without Claude Code (but details and caveats in another story).
As the frontier models have applied ever more brute force to their method, they have been able to perform harder tasks with acceptable quality. So our use has shifted with their capabilities. And so has the cost. The stuff we did early 2023 — and still do today — has indeed become ‘too cheap to meter’ as budget models can handle them well enough. But what about the other types of tasks?
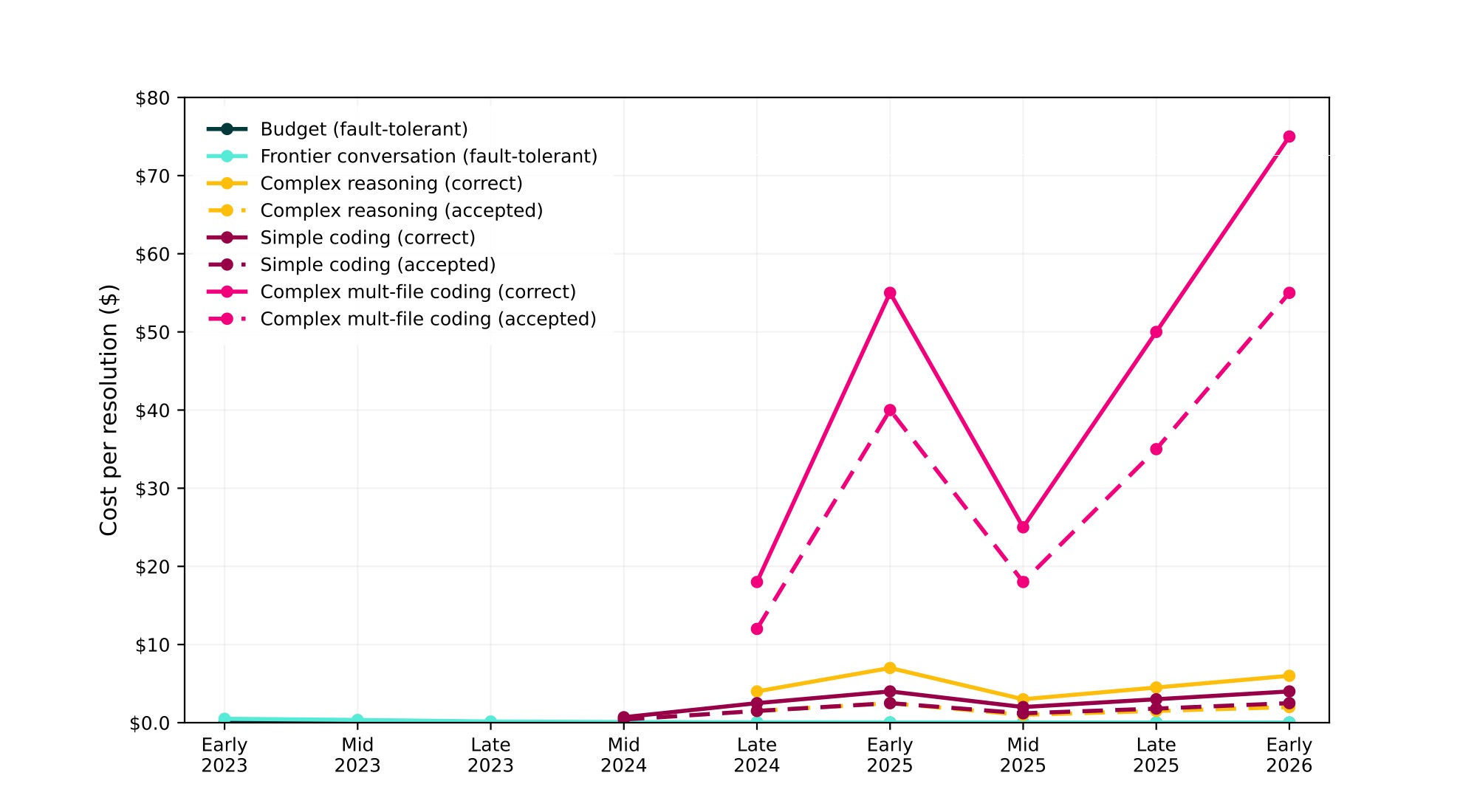
Here is the first graph. It shows the development of cost (again: while results improve, coding with LLMs in 2023 and 2024 was almost impossible) of the standard queries with budget and frontier models, as well as complex reasoning and simple coding tasks with the recursive models.
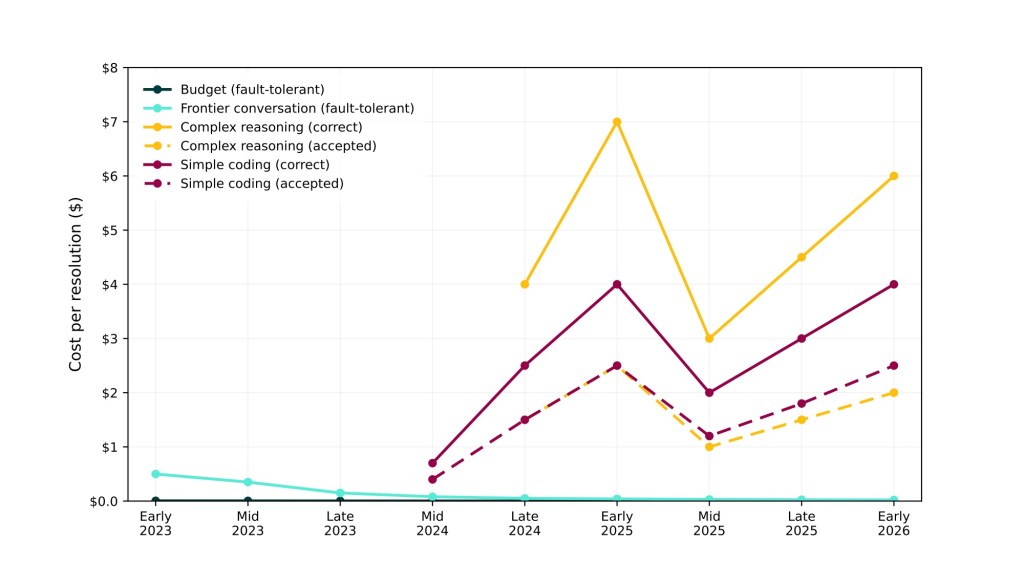
Figure created by Renske Wierda based on Claude’s data
So what do we see here? Well, while cost for simple things has come down — indeed this may be ‘too cheap to meter, and the growth of brute force has made things feasible that weren’t feasible before, like coding (within limits). A simple coding task in a small code base (or none) might cost something like $2-$4. But the effort — and with that the cost — per more complex tasks/quests has risen dramatically. There is a huge dip, which is when Claude Opus suddenly dropped to a third of the per-token price. (Why this happened is an interesting question (it doesn’t seem extremely likely to me this was all a 300% efficiency breakthrough), but the trend has stayed the same even if the sudden price drop did reset the graph).
Interestingly, because because it is much harder for the user to judge the correctness of ‘hard reasoning’ tasks than it is to judge the correctness of code (code is brittle and many errors will soon show when the result is used), the gap between ‘accepted’ and actually ‘correct’ for ‘hard reasoning’ is larger than for coding. (These gaps come from estimation on how many back-and-forths you need to get an accepted or correct result, for which Claude Opus 4.6 high produced some data).
But serious coding on reasonably sized code bases is quite a different story:
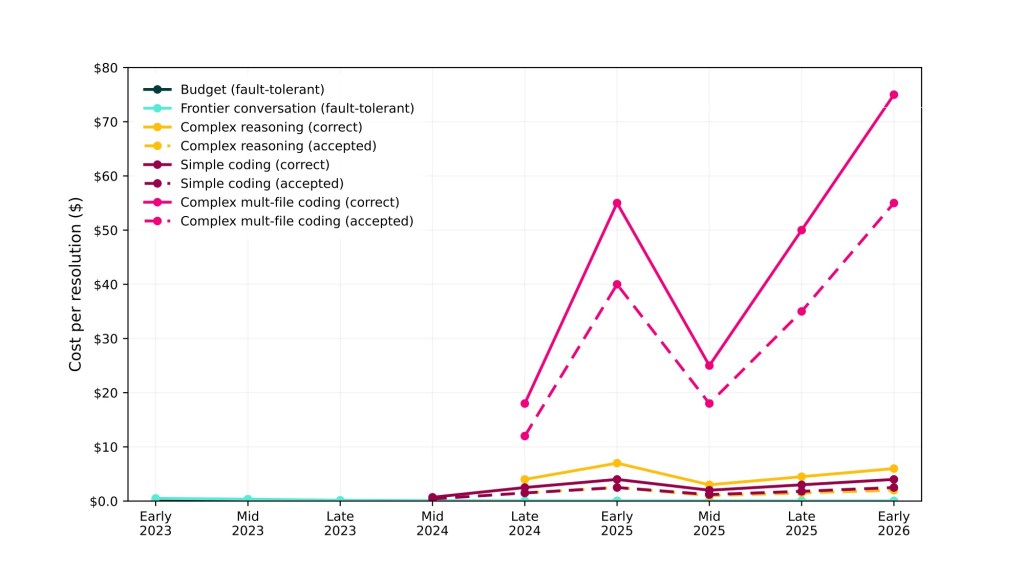
Figure created by Renske Wierda based on Claude’s data
The really hard stuff — for which making correct changes in a medium-sized code base of about 40k lines (my test project) is a good proxy (though with caveats) — seems to have completely exploded in cost, because doing that reasonably well requires exponentially more calculations, a growth that completely dwarfs the cheaper per-calculation cost.
Which implies that actual coding cost per task has exploded. Note that we are talking about solving a single task/quest in a code base at API-pricing costing somewhere in the neighbourhood of $65. A programming job with humans in the loop (the only one I think that makes sense given the risks) will see several of those in a day.
Let’s go back to my experiment. When I moved to the $100/month subscription, I almost never did hit my usage limits anymore (mostly because I’m not doing this full time, on the contrary). But at one point — after a massive change in the entire code base that meant a real big effort for Claude Code — I hit my 5-hour limit again. That gave me the possibility to continue with the same I had been doing but now at API-cost (which is the cost-type we have been talking about until now): I gave it $20 to spend at API-rate and 20 minutes later that had been spent.
Yes: $20 in 20 minutes. And note, that did not complete a full resolution of the — large but superficial — change that had been planned and that Claude was busy implementing. Recall, I have seen a single query use a million tokens before, and at API output token rates that single query would have cost me $25. A serious software engineer working full time on a reasonably sized code base may do 5-10 such tasks on a day.
At the beginning of 2023, we were talking about, say, 200 tokens in and 400 tokens out for a query. And not a lot of hidden or dark tokens. And now, the scaling has exploded, the use of water and energy has too. [Aside: these days we do not measure data centers in TFLOPS (amount of actual performance you get) but on GigaWatt, so not the performance of the car, but how much gasoline it slurps. That is remarkable in itself, and it is reminiscent of “a race to build the world’s heaviest airplane…] (As I wrote earlier in simpler LLM times: we have never seen a linear link between scale and performance, it’s more ‘exponential brute force growth delivers linear — after a while even slower — improvements’. Scaling doesn’t solve this. (Real fun: I actually roughly estimated then — from GPT-3 numbers — that to get to human-level performance you would need to scale to ~3,500,000,000,000,000 the size of GPT-3. Ouch. By the way: I have seen nothing yet that changes that estimate substantially. So some will get useful tools, but we certainly won’t get AGI from scaling — and that includes scaling via trial-and-error generation and use of symbolic parts).
Anyway, back to my experiment and the final test project. Apparently I have been doing stuff for $100 a month that would have cost me that several times over if I had been paying API-rates. Now my experiment is still ongoing, but I have drawn/made some tentative economic conclusions/estimates (some corroborating what others have been saying already, this is of course not entirely new — though the intersection of engineers really using this technology to build something serious with those that are critical/skeptical is probably not that large).
My test scenario is by far not the worst one. I am doing ‘human-in-the-loop’ (for good reason), which means I can’t burn tokens as fast as possible. I am working from a greenfield start, so there is not a lot of crud making things hard for Claude Code. Even with ‘human-in-the-loop’ and not doing this fulltime, using the stats Claude Code can show me, I have paid $100 for 4M tokens at API-price, and $180 for subscription, and that subscription used tokens that at API-pricing would have cost me about $450. This is a subsidy factor of 2.5, I can pretty confidently say, will be a bottom line for the subscription level subsidy for a Max account that is actually used for coding. But I also know how much of my weekly limits I hit, which is about 20% currently. So, max up to the weekly limit (using unrestrained ‘agentic’ use with no permanent human-in-the-loop for instance — a really bad idea, but that is for the other story) and the max subsidy factor will become roughly 12. (By the way, ‘full agentic’ means simply letting the LLM loose on your system without supervision, letting it generate and execute scripts at will there, something I think you really only should do if you have isolated that system from anything valuable).
In short: brute-forcing that really complex stuff, like editing code, might be the ‘killer application’ that currently is used to sell the Generative AI business as a usable tool to the world (and even as a road to AGI with Anthropic’s suspicious blog post on ‘recursive self-improvement’). But the actual costs are kept hidden from view for many users if they use subscriptions.
So what are my tentative conclusions?
- This ‘brute force code editing’ party cannot last. Really, it can’t. Would I have started this experiment for ~$1200/month? Nâh. Can they keep subsidising coding-support at this level? Definitely not. Can we do with far less programmers if you give them this tool at real cost? That is something for the other story if I get around to it. For now: the party probably lasts until the IPOs when reality must eventually hit.
- I suspect that I understand one driver for Anthropic’s developments since Opus 4.6. Both Opus 4.7 and Opus 4.8 clearly are not applying as much recursive brute force as Opus 4.6 can. See this Reddit thread for some of the comments after 4.8 was released. Opus 4.6 is in my experience the best so far (and, sure, it has enabled me to build that system that I would otherwise not have been able to in such a short timeframe), but my experience too is that 4.8 is a step down from 4.6. My personal guess is that the subsidy factor is already a very nasty problem for Anthropic (and OpenAI) and that they are struggling to keep close to the best ‘oversized brute force’ qualities while not burning that much cash that they won’t make it to the IPO in one piece. It definitely does smell a bit like a combination of desperation and ‘pump and dump’.
- Not providing Mythos to the general public may in part have simply been because it is far too expensive for them to run. I listened to a presentation of one of the Glasswing partners recently, and they mentioned as an aside that single tasks investigating their own code, could cost them $35k in API-cost. That is 1.4 billion — with a ‘b’ — tokens for a single task.
- There are more reports about actual cost versus what people pay and I tend now to find these ever more convincing. Complex coding has become the poster child of Generative AI, but if I really do this in a serious way (decent code base, and I know code, so I can actually see if the system starts to mess up the quality) I need to use a lot of brute force using a recursive/extended model, and they may be making $10 loss on any $1 I spend, if not more, if I do this full time.
- Situations that are fault-tolerant, like trying to find vulnerabilities and exploits in existing code based on the patterns encoded in LLMs, might be affordable for large players such as state actors.
- Anthropic’s post on ‘recursive self-improvement’ lacks even the most basic critical approach as well as any number on the cost of all that edit-code-inference. But they need it on the way to their IPO, I guess.
Which leaves open the other key question: how good is that code anyway? Which is a different subject for a different time.
So:
- Enjoy it while the party lasts (and for me it probably either ends when they retire Opus 4.6 or have their IPO and economic reality comes knocking).
- And prepare for when it ends, and you maybe have maintain the code that heavily subsidised ‘brute force’ has gotten you. (IT was one of such actions where a single query cost me a million tokens).
Caveats
The preparation of this article has differed a lot from my normal way of working. For one, I don’t really use an LLMs for serious analysis (search is really helpful, though). Too unreliable, and that was clear now too: I had to travel through several erroneous scenarios, e.g. where I was presented with Opus 4.6 data combined with (three times as expensive) Opus 4.1 pricing (“My apologies…” said Claude. Again.). But the overall gist is, I suspect, more or less correct. Now, if you are a big believer, and thus my critical story must be wrong, remember it is based on what Claude Opus 4.6 ‘thinking’ at ‘high effort’ produced/found for me…
Good data is almost impossible to get. You can look at Opus 4.6 pricing, but there are various levels of ‘effort’ that influence how many tokens are used. What we do know is that is that the hidden ‘recursive’ tokens are billed at the price of output tokens. But how high you have to set your effort to get the sweet spot between ‘dumb/bad code’, ‘good enough results’ and ‘careening off track and lost in the woods’ cannot really be estimated. So, I have used by own experience of the last few months also in the back of my mind. It is all an educated guess, nothing more. But my stats from my personal use are pretty hard, so we have at least some hard, but anecdotal, evidence.
Am I someone who has a year of experience with everything ‘vibe coding’? No. I’m still (the rusty remains of) a classical software designer/engineer. Enough of a software engineer, by the way, to be able to recognise good and bad decisions by Claude Code, and to experience a real speedup in my experiment. At this level of subsidy, it is definitely worth it for someone like me, with the project I am doing.
Final thought — a AI-lesson from 30 years ago, applicable today
Why has ‘brute force code editing’ become so good? (Again: for the caveats on ‘good’, wait for the other shoe (i.e. article on this blog) to drop.)
Here is something I remember (warning: memory is in part fantasising about the past to support your current convictions) that offers a perspective. When, in the second half of the 1990s, I worked for the Dutch Advisory Council for Science and Technology Policy (a government think tank filled with top people from academic science and technological business, I was a scientific staff member — they actually hired people with real technical experiece and experience and not just powerpoint shamans) part of my job was to read a lot of science journalism. And I came across a short research note in a US science magazine — I think it was Scientific American — that said researchers at USPS had been able to increase automatic handwriting recognition to something like 76% success rate, up from something like 71%, the top in the world at that time. Now, such technology was in hot demand at postal operators so they could automate most of the sorting of letters, saving a lot of cost. 76% was of course far from enough to actually use this.
But the note surprised me, because I knew the Dutch postal service (PTT Post at the time) already was using automatic address recognition in production with over 99% reliability. So, the question obviously was: how? It turned out that there were two basic technologies at the time. One was based in pixel-based pattern recognition, the other was based on extracting a vector-based representation of the handwritten address. The pixel-one had a lot of trouble with sizes, the vector one had trouble in other ways. Both had that same slightly over 70% success rate. But what PTT Post had done was combine the two. Which still did not give you accurate results, but then some brilliant engineer had the following idea (I think comparable in brilliant creativity to Vaswani’s trick that led to the current LLM-boom): the actual combinations of different parts of addresses were a far more limited target space than writing in general. Not just that some cities and street names simply do not exist, but especially that combinations do not exist. It went like this: suppose your top matches for the city are ‘Amsterdam’ and ‘Amstelveen’ (all checked as placenames that have to exist somewhere). And your top guesses for postal code characters were ‘1/2/8/4/A/B’ and ‘7/5/3/8/H/B’ and your top guesses for street name were ‘Westerstraat’ and ‘Weesperstraat’ (Note: all these except the city names are not real examples), then together these low-reliability guesses could turn into a single high-reliability result. E.g. when there wasn’t a ‘Westerstraat’ in ‘Amstelveen’, this combination could be skipped. And if no postal code of any of the top city/street matches would start witha ‘7’ that could be dropped too. Etc. What they did was limit the actual freedom for results so much that the mediocre algorithms of the day could cope.
I am thinking about this because math and code are areas that have some of that. Code is not poetry — though some code is elegant and beautiful — and there are a lot of constraints that make the area have much less degrees of freedom that, say, a normal everyday question you can ask an LLM. Especially with the indirect/recursive use of LLM, and the absolute checks possible (“does this compile?” “does it produce exactly this result in a test?”) the essential inaccuracy of Generative AI can be effectively constrained (though at a high cost in — invisible — trial and error). Hence, code and math are ‘specially constrained domains’ and the fact that we can do much more in them that others is not a sign that Generative AI is getting more intelligent, but that it is being applied in massive scaling and recursion in a domain that has all these combinatory restrictions that help weed out undesired results. Just like 30 years ago when trying to read hand-written addresses.
Methodology & assumptions (by Claude)
Resolution = total cost until the task is done, including retries, backtracking, failed attempts, and context resend across all turns. “Accepted” = user stops because output looks right. “Correct” = verified to actually be right (tested, audited, cross-checked).
No caching. Prompt cache TTL is 5 minutes (1-hour option at 2× price exists). For human-in-the-loop workflows where turns are typically 10–30 minutes apart, cache misses are the norm. All estimates assume full-price input on every turn.
Top model at each period: GPT-4 (early 2023) → GPT-4 Turbo (late 2023) → GPT-4o / Claude 3 Opus at $15/$75 (mid 2024) → o1 at $15/$60 (late 2024) → Opus 4.0 at $15/$75 (early 2025) → Opus 4.5 at $5/$25 (mid 2025, 3× price drop) → Opus 4.6 at $5/$25 (late 2025) → Opus 4.7 at $5/$25 with +35% tokenizer inflation (early 2026).
Thinking tokens are billed as output tokens ($25/MTok for Opus 4.5+). On high effort, thinking can be 30–50K tokens per turn, invisible to the user (redacted on Opus). On medium effort, ~76% fewer thinking tokens with similar quality on most tasks.
Complex multi-file coding assumes a 35K+ line codebase, 15–25 tool-call turns, cumulative context resend without caching, high effort extended thinking. The $55–75 range at early 2026 reflects Opus 4.7 pricing ($5/$25) plus 35% tokenizer inflation on ~5–7M cumulative input tokens.
The mid-2025 dip is real: the 3× Opus price drop ($15/$75 → $5/$25) temporarily reduced costs even as task complexity grew. By late 2025, harder tasks and higher thinking budgets pushed costs back up. The 35% tokenizer inflation on Opus 4.7 accelerates this.
The reasoning gap between accepted and correct is ~3× because most reasoning faults are invisible to the user. Verification requires independent methods, cross-model checking, or domain expertise — all of which cost additional tokens.
Sources: Anthropic pricing page (platform.claude.com/docs/en/about-claude/pricing), OpenAI pricing, Anthropic engineering blog (April 2026 postmortem on effort settings), claudecodecamp.com session tracking data, Branch8 team cost analysis, Faros.ai developer cost averages, Verdent/Finout/MorphLLM pricing guides, Epoch AI energy analysis, OpenRouter State of AI 2025.
P.S.
I have looked shortly at OpenAI/GPT-5.x/Codex pricing and it seems the numbers are roughly comparable.
Full transparency: the conversation with Claude that was used for the production of this article can be read here.
[Update 07/Jun/2026: The initial post featured figures with an error (solid and dotted lines were switched). This has been repaired.]
[Update 11/Jun/2026: there has been some feedback about using caches or not. Let me add a session info from just now:
Session
Total cost: $15.59
Total duration (API): 18m 3s
Total duration (wall): 2h 13m 16s
Total code changes: 232 lines added, 80 lines removed
Usage by model:
claude-opus-4-6: 1.5k input, 41.8k output, 26.4m cache read, 212.6k cache write ($15.59)This shows that these 18 minutes would have cost $15.59 and it would have cost that — cache and all.]
[You do not have my permission to use any content on this site for training a Generative AI (or any comparable use), unless you can guarantee your system never misrepresents my content and provides a proper reference (URL) to the original in its output. If you want to use it in any other way, you need my explicit permission]

Ctrl + F “DeepSeek”
no results
close tab
LikeLike
very interesting and I would say this roughly pairs with my intuitions of using the llms. One question,, I would expect that correct answers would cost more than acceptable answers since they would require more interactive queries cycles to converge on the correct result. Can you explain why that acceptable cost more? Perhaps I am not understanding something in your methodology.
LikeLike
The initial figures were erroneous which was discovered shortly after publishing. They have been updated.
Thanks for pointing it out.
LikeLike
Note, the $1000 estimate is for the most extreme full-agentic mode. My personal factor is around 2.5x so far.
LikeLike