A while back, I wrote the post Modelling Homogenous Landscapes in #ArchiMate (Classes and Instances), which was a first post on modelling detailed infrastructure landscapes. Assuming you’re with me that a modelling language is very useful for large complex situations, but doesn’t add that much value to simple diagrams, we can delve deeper into modelling large infrastructural landscapes in enough detail so that useful analysis is possible.
Note: You can use ArchiMate for high-level abstract models and for detailed models, it is your choice. This post is about the detailed and precise use, if that’s not your cup of tea, just read this for entertainment and to think about the effects of choosing your patterns in general.
Also, let’s get one thing clear from the start: the fact that I like my detailed administration of the Business-IT landscape to end up in ArchiMate models does not mean I think you need to model the entire enterprise in all its glorious details by hand. In fact, the more we are able to automate discovery and verify it against reality, the more powerful we can be. But getting this data in an ArchiMate model opens the data up for a lot of useful analysis and reporting.
That, by the way also doesn’t mean we need to use a big single setup such as some CMDB to model ‘everything’. I strongly believe that the different uses of different structured administration makes it unlikely (if not just a pipe dream) that you can do everything with a single model. And as ArchiMate’s derivation relation shows, creating meaningful derivations (summaries, shortcuts) with a purely syntactical operation is ineffective — which is not unexpected for those who have thought about the differences between grammar (and logic) and meaning. The best setup will have several ‘models’ (structured administrations), but with the added requirement that these are coherent with each other, with each model supporting a different specific set of uses, but all illustrating a different aspect of the same landscape.
One of the models in such a landscape of models can be a large and detailed ArchiMate model. And the rest of this post is about patterns for building such a model (again: whatever the mode of discovery and verification — it might in part be built directly from a CMDB).
 Final Note: this post might be considered about advanced ArchiMate (pattern development) and if you are new to ArchiMate, please do not get scared away from the language because of the complex things we can do with it (actually we can do that because the language is pretty powerful). If you’re a non-native beginning German speaker, you would not get scared away from German because of, say, Doktor Faustus by Thomas Mann, would you? (Not that this is as difficult as Mann, far from it.)
Final Note: this post might be considered about advanced ArchiMate (pattern development) and if you are new to ArchiMate, please do not get scared away from the language because of the complex things we can do with it (actually we can do that because the language is pretty powerful). If you’re a non-native beginning German speaker, you would not get scared away from German because of, say, Doktor Faustus by Thomas Mann, would you? (Not that this is as difficult as Mann, far from it.)
Modelling large landscapes
Landscapes can be large but homogenous (Spotify, Apple, Microsoft, Google, Amazon, etc. all have large landscapes of identical systems, both infrastructure and applications). Landscapes can also be heterogenous. In this post, I am looking at how to model homogenous landscapes, which means that there is a lot of repetitive information in the model, and we want to prevent somehow that we need to model the same pattern over and over again.
Let’s start with a basic example, focusing on the infrastructure. We have a reporting application that uses two pieces of infrastructure: an IIS web server and a SAS runtime environment. As modeled in standard Mastering ArchiMate pattern, we Aggregate the required infrastructure under an ‘Exploitation’ Infrastructure Service. This ‘Exploitation’ service Aggregates two specific Infrastructure Services, each of which is Realised by a Node:
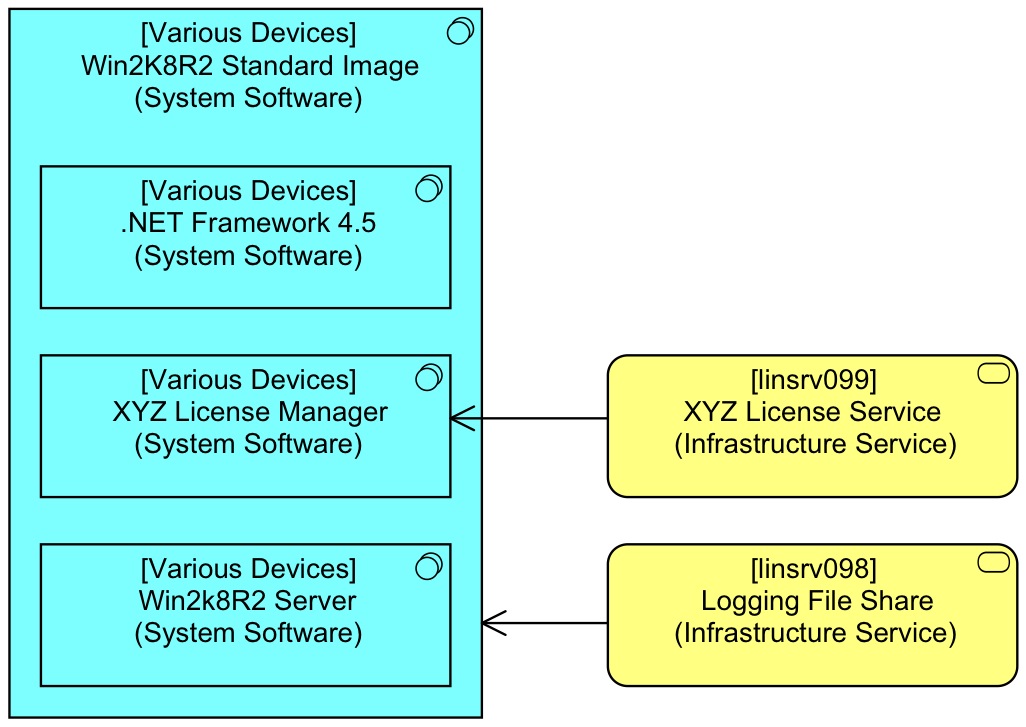
 We’ve made things a little interesting by having one virtual server and one physical. Still, we see that there is a lot of repetition (which will be even more so if you have hundreds or even thousands of — possibly virtual — servers). All of our Windows servers have Windows 2008R2 (yes, this is an older example), an XYZ License Manager agent and the .Net Framework 4.5 are part of the standard distribution. The XYZ Licence Manager connects to some central service. And all our Windows servers use a central logging file share in case we do classic file based logging.
We’ve made things a little interesting by having one virtual server and one physical. Still, we see that there is a lot of repetition (which will be even more so if you have hundreds or even thousands of — possibly virtual — servers). All of our Windows servers have Windows 2008R2 (yes, this is an older example), an XYZ License Manager agent and the .Net Framework 4.5 are part of the standard distribution. The XYZ Licence Manager connects to some central service. And all our Windows servers use a central logging file share in case we do classic file based logging.
The idea now is to remove repetition. We can do that by reducing all the repeated elements by a single one that represents them, for instance, our re-usable Win2K8R2 distribution could be modelled like this:
Now, we need to make clear our two servers are based on this reusable element (the image). Here is one way we could do it:

We just use that same element in every server Node we model. This is nice, but the Nesting does hide a slight problem as it doesn’t show the actual relations. Nesting, in this case is normally Composition, but then our Win2K8R2 image has multiple composite parents in ArchiMate and that is not allowed (no tool will stop you as far as I know, though). So you must make sure the relations are Aggregations. Do that and expand the Nestings and you get:
 Which incidentally shows we already had that multiple-composite-parents problem with the virtual Device (mentioned in the book. I think this UML-derived limitation for the Composition relation is useful in IT, but less so in EA, but I digress).
Which incidentally shows we already had that multiple-composite-parents problem with the virtual Device (mentioned in the book. I think this UML-derived limitation for the Composition relation is useful in IT, but less so in EA, but I digress).
There is another way we can do this. We may use a single representation for the template (the distribution ‘image’), but separate representations for all its actual copies, of which each is unique (and in reality, a system manager may even adapt it without adapting the original template). We then get something like this:
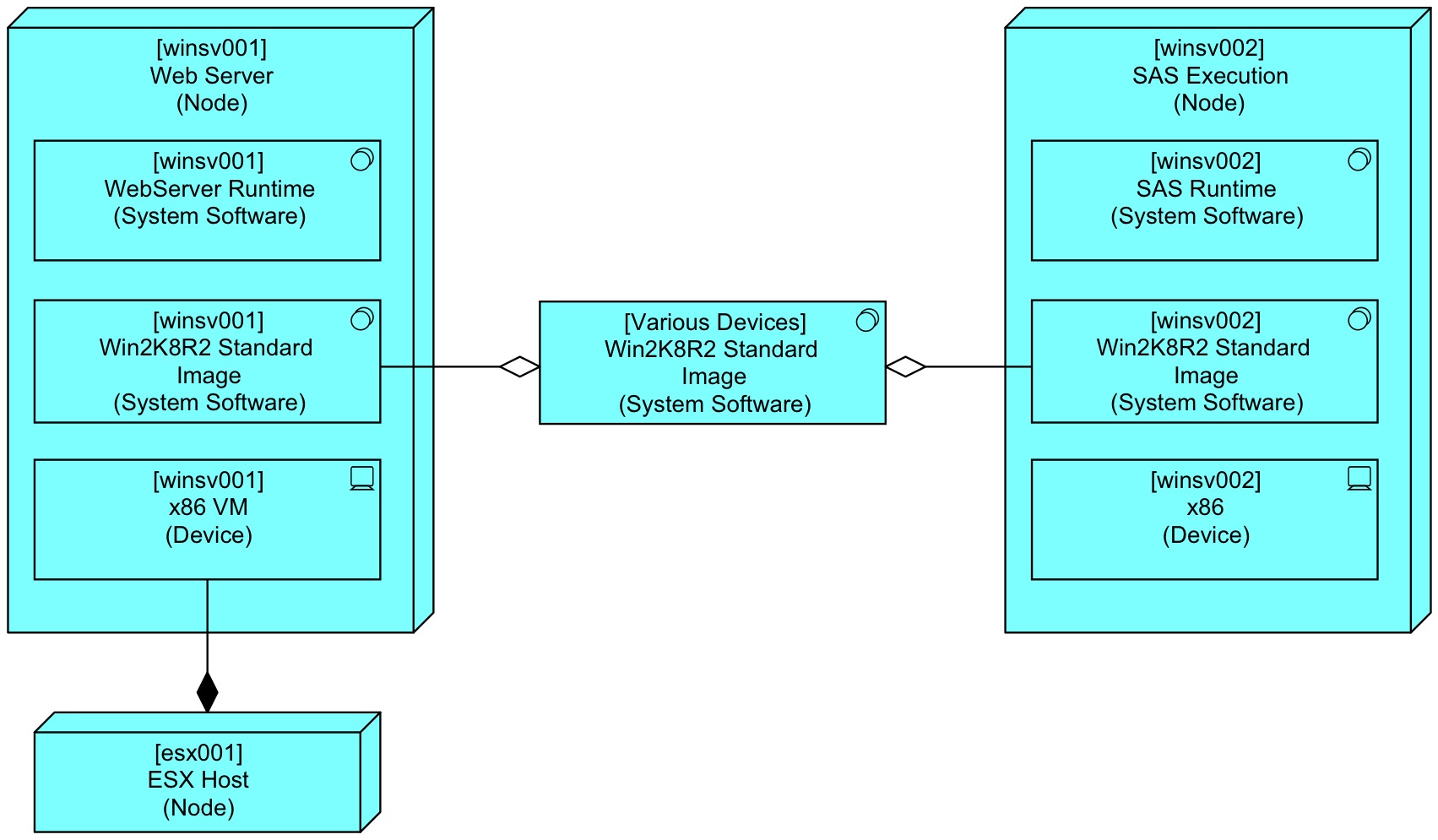 Here, we use the re-usable element as a collection of all the instances we have. A really good ArchiMate modelling tool would probably support this via ‘templates’, filling in the correct label information based on the template and variables. (But now I’m dreaming.) This is not my final solution to the problem of Re-Usable modelling for infrastructure, though.
Here, we use the re-usable element as a collection of all the instances we have. A really good ArchiMate modelling tool would probably support this via ‘templates’, filling in the correct label information based on the template and variables. (But now I’m dreaming.) This is not my final solution to the problem of Re-Usable modelling for infrastructure, though.
At this stage it is wise to revisit the post about analysis of ArchiMate models. How many ways have we now seen that relate an application to underlying Infrastructure Services used? How many different routes are there between the application and used Infrastructure Services such as the [linsrv99] XYZ License Service (Infrastructure Service) and the [linsrv098] Logging File Share (Infrastructure Service)?
I generally try to minimise the variation in patterns in a model, but here we might want to loosen that strategy. Let me explain:
Multiple-Path Modelling
As long as paths are unique, there is nothing amiss with having multiple paths in your model between A and B. In the book Mastering ArchiMate, I have shown a common basic pattern for a Node. Here it is again for one of the Nodes above:
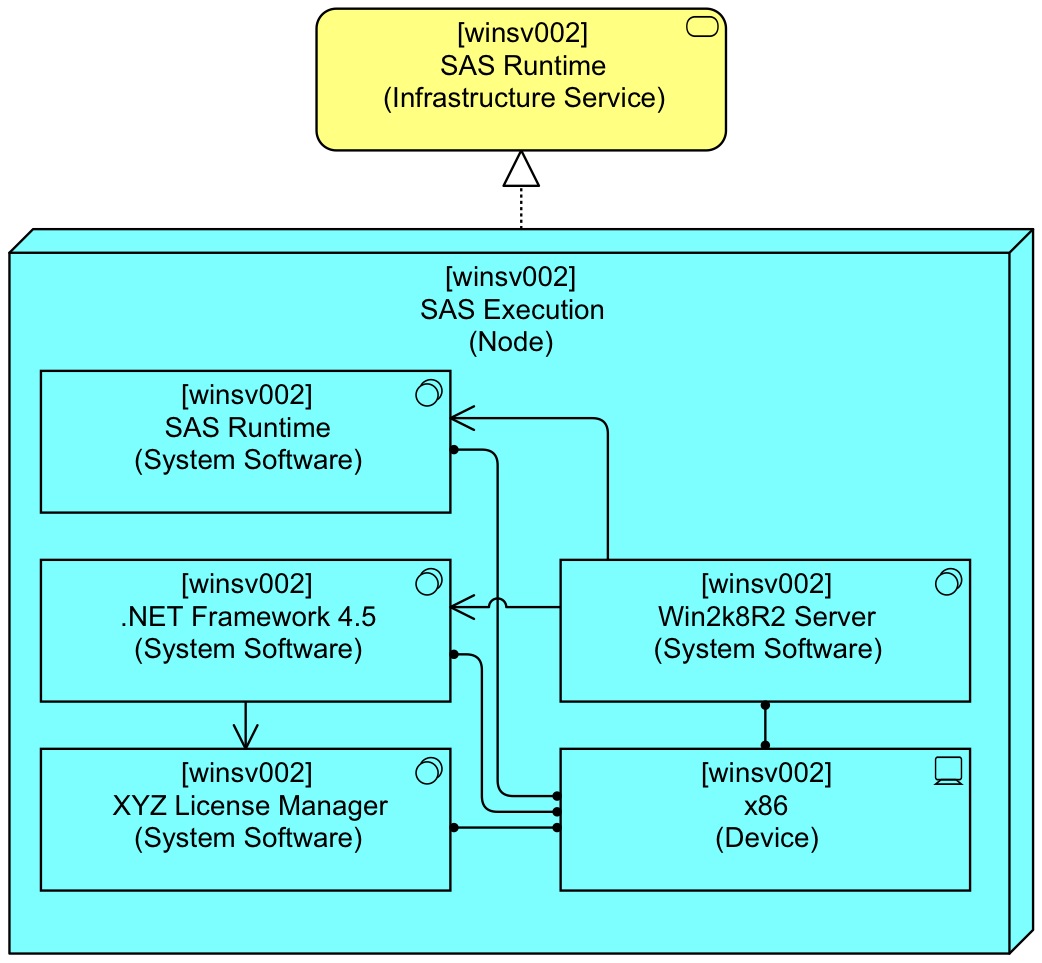 The Nested elements are all Composite children of the Node. A couple of design choices have been made here:
The Nested elements are all Composite children of the Node. A couple of design choices have been made here:
- We Realise an Infrastructure Service directly from the Node and not from one of its constituent parts. We thus use the Node as an encapsulation of the inside details, so in other views we may just see the Infrastructure Service and possibly the Node without the internal details, and we still are complete;
- We Assign all System Software to the Device. Actually it would make more sense to Assign software installed on the OS to the OS, but ArchiMate does not allow Assignments from System Software to System Software (yet?). Besides, we would get a many-level structure which is hard to use for automated analysis.
- We use (actually derived) Used-By to model internal dependencies. E.g. our XYZ License Manager may depend on the .Net Framework 4.5 but the SAS Runtime does not.
The book is not very detailed about Nodes using Infrastructure Services in some way or another. Modelling is focused on how a business uses IT, not the intricacies of IT itself. What there is, in the book, is Used-By between Infrastructure Services, or — to model heartbeats in High-Available patterns for instance — Flows between elements inside different Nodes. But in this post we are looking at modelling infrastructure itself in proper detail, and setting up a real philosophy for that. For that, I’ve decided that I need to extend my standard Node pattern. Here it is:

What I have done here is model both the relation with the encapsulation (the Node) and with the internal elements explicitly. This is different from the book and it might seem confusing at first. After all, why model two ways to show the same? The answer is that we want this structure in our model to be able to perform the right analysis. Just connecting to the Node is not enough: for some questions we need to be able to differentiate between, say, XYZ License Manager and SAS Runtime if we want to know what depends on XYZ License Distribution. This structure enables us to answer more types of questions. On the other hand, we do not want to have to use the internal details every time, so the relations that connect to the encapsulating Node itself are useful in situations where we want to show a less detailed picture. E.g.:

Without the relations to/from the encapsulating Node, I would always need to add internals to show the relation in a view. That clutters views up and makes communication more difficult than it already is.
I coloured the different Realisations and Used-By’s for a reason: the red relations can be derived relations from the orange ones and the Composition between the Node and its constituent parts. As I’ve written elsewhere, ArchiMate’s derivation mechanism is problematic and in reality it is never used as it was originally intended because of its limitations. The derived Realisation relation above is unproblematic. But the Used-By to the encapsulating Node is problematic. Can you see why? Free Mastering ArchiMate PDF for the first commenter who gets it exactly right in a comment added to this page below (previous winners of quiz questions and (former) members of my team(s) at work are excluded from winning). (Note: there is a second question at the end that is also part of the quiz that is part of this post.)
The solution: a new basic TI-pattern
Now, we can look at the solution for patterns that enable reuse modelling in ArchiMate models of infrastructure. First, I am introducing a new (different from what is in the book) basic pattern for encapsulating infrastructure in a Node:
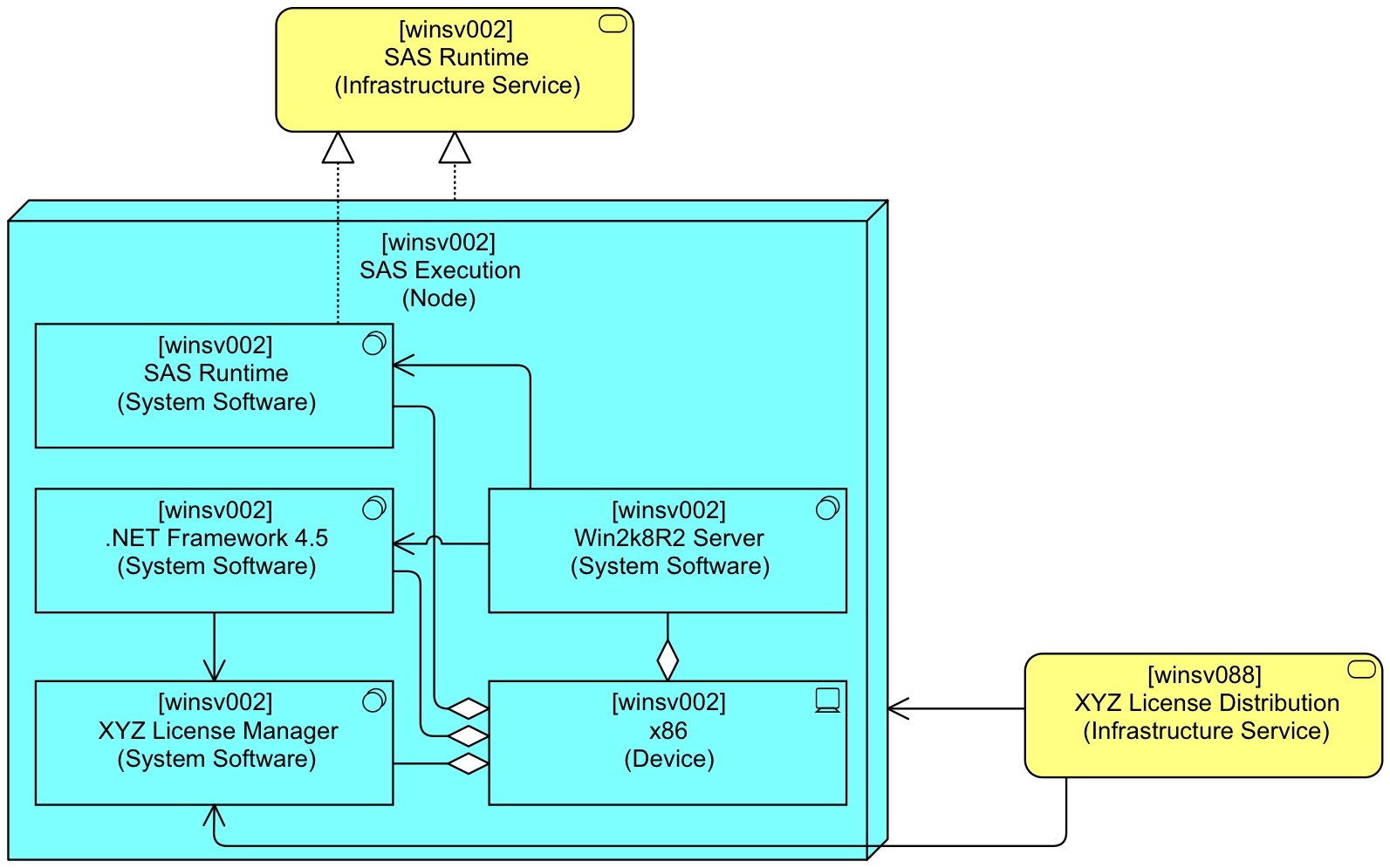
This pattern differs from the basic pattern in Mastering ArchiMate Edition II in a couple of ways:
- It uses Aggregation instead of Assignment for relating System Software with the Device. This repairs the use of a leftover from ArchiMate 1: the Assignment between Device and System Software. In ArchiMate 1, System Software was a behavioural element, and it was the behaviour of the active Device element. In ArchiMate 2, Infrastructure Function was added and System Software was rebranded as an active element. But the Assignment between Device and System Software was kept, partly I suspect for backward compatibility. In the Mastering ArchiMate book I discuss the role of this Assignment relation in detail in Section 27.3 Fuzzy Concepts. But Assignment between System Software and System Software was not added to ArchiMate 2 (which is an omission, I think). I do not use Composition, because I want to be able to reuse parts of a configuration, as explained below).
- Using Aggregation for deploying software on software enables us to actually deploy .Net, SAS or the License Manager on the Windows System Software, but I don’t do that because of the extra layering complexity that brings.
- It models both the relations to the internal elements and the relations to the encapsulating Node. We lose the ‘pure’ encapsulation approach. Note: this is only practical in the infrastructure layer of ArchiMate, because it has that abstract Node element that is generally used for encapsulation. Such an abstract element is unavailable in the other layers. In the application and business layer, we would have, for instance, Application Component encapsulating Application Component, in which case we could not differentiate anymore between relations with outside and inside elements in our analyses. In this case, we always know that if we connect to Node, we are connecting to the encapsulating element. If we connect to System Software, we are connecting to internal details, the encapsulated elements.
In a reuse setting, this becomes (with the actual server on top and the reusable software image at the bottom in one view):
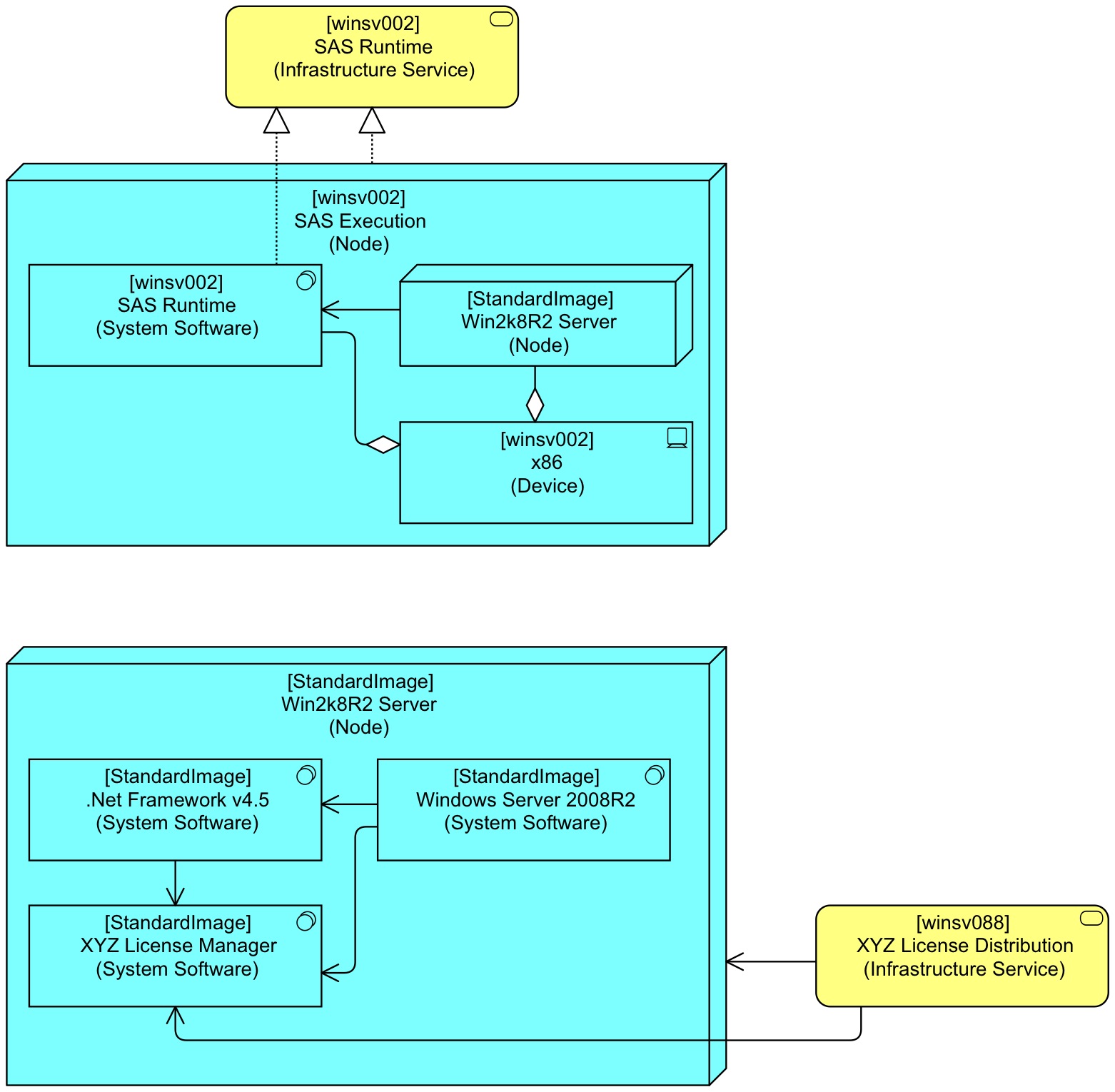
Note that the single object [StandardImage] Win2k8R2 Server (Node) appears twice in the above view, but it remains of course a single element displayed twice. Here we see ArchiMate’s model/view separation in action. The following view of exactly the same model, but without displaying the same element twice, makes perhaps more clear what is actually going on:
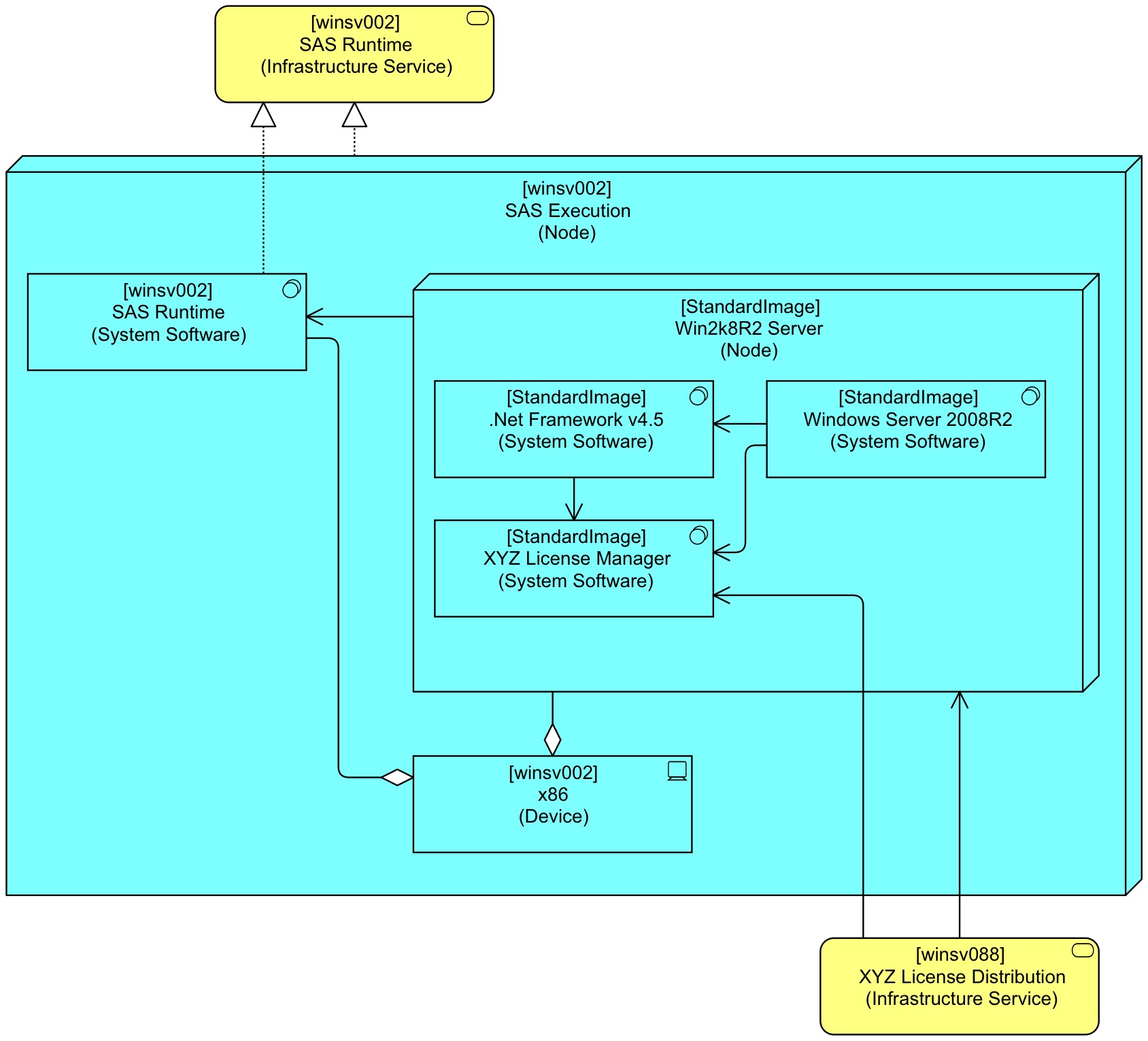
Second quiz question: there are a few problems lurking here with a common cause. Which ones?
If this quiz question has been answered, I’ll present my real solution.
If ArchiMate 3 will allow Assignment from System Software to System Software (meaning: deploying one System Software element on another), I will change the internal Aggregation relations back to Assignment and I will change the Node as a ‘reusable element’ back to System Software because of the following disadvantages of the current solution: Reusable system software is now modelled as a Node. It would be more appropriate if it was modelled as … System Software. We cannot do that now because the internal structure of a reusable element would then differ from the internal structure of a standard element, thus adding to the complexity of the number of patterns to take into account. We want a single pattern for Nodes wth or without reuse, and that means we need to use Node and it means we cannot use Assignment.
The question how deep you want your reuse levels is up to you. The deeper, the more difficult automatic analysis and reporting. The less deep, the more duplicate parts of patterns you will see.
PS. I’ll be speaking at Gartner’s EA Summit 2015 London UK on May 2oth and at the MBT Congres in Houten NL on May 21 about Chess and the Art of Enterprise Architecture. Modelling your current state in Enterprise Architecture for me is like knowing your position before making a move in chess. Rather useful. And ArchiMate is a decent language to do this modelling in.

Gerben, as always a great article. Very useful for me as infrastructural architect.
The answer to the first question is that the direction of the Composition relation between the XYZ License Manager and the encapsulating Node is reverse to the direction of the Used By relation between XYZ License Manager and the XYZ License Distribution.
The direction of a Composition relation is from parent to child thus in this case from encapsulating Node to XYZ License Manager. The direction from the Used By relation is from XYZ License Distribution to XYZ License Manager. This doesn’t make a valid derived relation.
For the Realization derived relation the direction is the same, so that results in a valid derived relation.
LikeLike
Hi,
To confirmed by Gerben of course, but the red derived Used-By is correct and results from:
[winsv088] XYZ License Distribution (Infrastructure Service)
Used-By (Orange)
[winsv002] SAS Runtime (Node)
Composed of (nested)
[winsv002] XYZ License Manager (System Software)
Regards
LikeLike
Jean-Baptiste is right. Both red relations are valid derivations of the orange relation and the Composition between Node and encapsulated System Software elements. I was not stating that the orange Used-By was derived. I stated that the red relations were derivations.
The problem with the Used-By from [winsv088] XYZ License Distribution (Infrastructure Service) to [winsv002] SAS Runtime (Node)is a different one.
LikeLike
Hi JB and Gerben,
Now I see that I interpreted the question the other way around. I was indeed saying that the orange Used-by isn’t a valid derived relation from the red Used-by. Of course the red Used-by is a valid derivation of the orange Used-by. But I find it rather counter intuitive to say that the relation between the XYZ License Manager and the XYZ License Distribution is a derived Used-by relation from the Used-by relation between container Node to the XYZ License Distribution. Intuitively the relation is a direct Used-by relation between the two XYZ License elements.
This raises another point (maybe Gerben is pointing at this with his quiz question): If the red Used-by relation between the XYZ License Manager and the XYZ License Distribution is a valid one, than there is also a valid derived used-By relation between the Win2k8R2 Server and the XYZ License Distribution. This is strange because the Win2k8R2 Server isn’t using the XYZ License Distribution. Same goes for the other SystemSoftware elements (SAS Runtime and .NET Framework 4.5).
LikeLike
Bingo! That was the answer on the first question that I was looking for. Now, the first one who answers the second question wins the prize (as he/she can also copy this correct answer to the first question).
LikeLike
“Second quiz question: there are a few problems lurking here with a common cause. Which ones?”
You mean, instead of the “framnework” (sic) 😉
LikeLike
In the pictures, indeed. Fixed now. Of course, as this is a real model with multiple views, I only had to fix the element once. (“Listen carefully, I will say theese only once…”, sorry, I digress)
LikeLike
“Second quiz question”
One flaw I see is that as soon as another node use “[StandardImage] Win2k8R2 Server (Node)” using an aggregation from a device, you’ll end up with derived UsedBy relations between those other devices and “[winsv002] SAS Runtime (System Software)” which will mess any potential automatic analysis.
LikeLike
A good step in the right direction 🙂
LikeLike
Agree. Messes automatic analysis up. It goes even further. If you e.g. have another instance of the SAS Execution (node) realizing another SAS Runtime (infrastructure service) then the SAS Runtime 1 (infrastructure service) is realized by the SAS Execution 1 (node) and uses the SAS Execution 2(node). Strange.
The modelling of reusable building blocks is something I have been struggling with for a longer period. The StandardImage is a reusable pattern, but when there are multiple nodes that reuse that pattern, they have unique instances of this pattern. By using associations the multiple parent issue is solved, but it still are unique instances. E.g. multiple SAS Execution Nodes each have their own XYZ License Manager.
Sometimes in an analysis you might be interested in relations with the logical building block (which nodes use this building block?) but sometimes you might be interested in the relations with the instance of the building block.
LikeLike
Gerben, please clarify the use of assignment and agregation/composition between software and device. I particulary use composition to describe the relationship between duas elements such as a device and a software, for instance, lets say, between a PC and a Operating System (OS), where the PC (device) is composed of an OS. Why I would use composition instead of agregation? Well, if the father dies (PC) the children (OS) will die along (as rule of thumb); whereas, if you describe it as agregation, the OS would still be alive if the PC died – false statement, would’nt you agree? And I would never use assignment, since it would be a good practice to only use it between ative and behavior elements. Thank you!
LikeLike
Hi Luis, I agree with your analysis.
I was using Aggregation because when you use a reusable element directly it would become the Composite child of many Devices and that is forbidden in ArchiMate.
But in my final solution (next post), I do not directly use the reusable element in each server, so I might indeed use Composition instead of Aggregation. Probably better too.
LikeLike