It is undeniable that ChatGPT, Microsoft’s CoPilots, etc. are improving on what was the state of Large Language Model (LLM) driven chatbots about a half year ago — which is really not that long. But, if you look a bit under the surface (which we will do below), you can spot a trend that LLM improvement itself is stalling. These are not contradictory observations, as we have entered the era of “Engineering The Hell Out Of (And Working Around) A Limited Approach”.
TL;DR
ChatGPT has acquired the functionality of recognising an arithmetic question and reacting to it with on-the-fly creating python code, executing it, and using it to generate the response. Gemini’s contains a trick Google plays to improve benchmark results that more or less boils down to “do not create a single answer, create 32, and use that to select the best one”. These (inspired) engineering tricks have one thing in common: they illustrate that we have reached the situation that LLMs themselves as a technology have plateau’d, and we are focussing to engineer the hell out of complex landscapes to improve results.
LLM development saw a disruptive change with Transformers in 2017, it has scaled in parameter volume until roughly a year ago (though 175 billion was already achieved in 2019), but enough that becoming larger apparently doesn’t really help much. Now the context (prompt) size has been massively expanded (GPT4: 128k) which opens up a lot of ‘prompt engineering’ under the hood, something that is now actively exploited by the players. The attention (pun intended) is switching from parameters to contexts/prompts. But we should not forget ‘prompt engineering’ is in fact a technique that compensates for LLM limitations (on ‘understanding’), which means that the massive switch to contexts/prompts is a de facto admission that LLMs themselves are a dead end, understanding-wise, that are destined to become just ‘dumb-creative’ elements in a wider landscape of technologies that make up chatbots and friends.
I like The Department of “Engineering The Hell Out Of It”, I do, as I am at least in part an engineer at heart (and even if I am interested in many more areas than engineering itself — but hey, even then, an engineering perspective can be really useful). The way Meta engineered Cicero — an AI that can play blitz-Diplomacy (a game of strategy and negotiations) really well — was in my opinion an impressive engineering example.
There are two activities from the last couple of months that I want to point out to you — and that I consider “Engineering The Hell Out Of it” — and then draw a few strategic conclusions from these.
OpenAI and Microsoft “engineer the hell out of chatbots”
In my EABPM talk last year I showed the following typical failure of ChatGPT at the time, when doing math:

This shows the tokenisation of input/output by LLMs and illustrates that ‘next-token-prediction’ — which really is all that LLMs do, the rest that they seem to do is an approximation based on that single mechanism — can go wrong easily (and in non-math settings often subtly). That this mechanism is only approximating reasoning and human kinds of understanding has been pointed over and over again by critics, but that has had little effect on the GPT-fever currently still on the planet. The small effect of ‘pointing out the errors’ is an interesting subject by itself with interesting links to how our own intelligence works (see this story about ‘convictions’, but I digress, as sometimes is the case…)
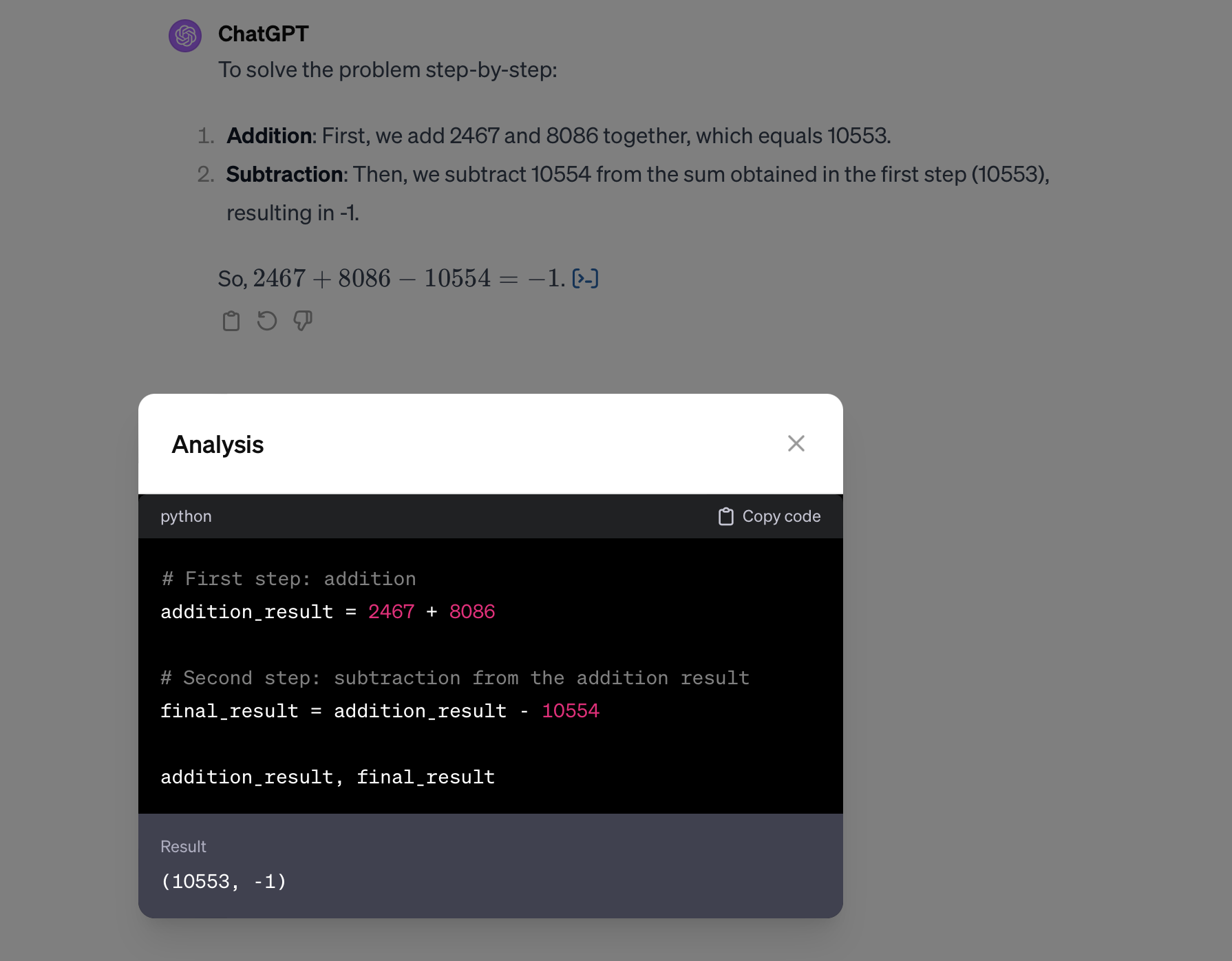
But these days, ChatGPT doesn’t so easily make these errors anymore:

However, I would like to draw your attention to that little clickable element on the lower right, outlined in red. When you click on this, the result becomes:
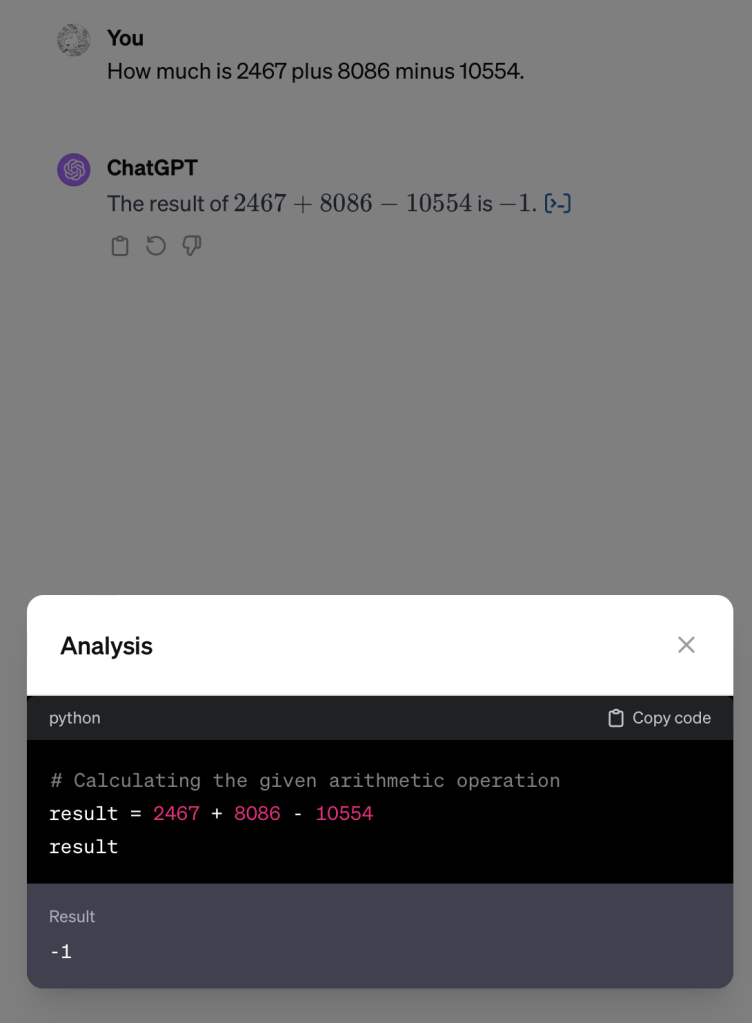
What seems to be happening is this:
- Your prompt is analysed, looking for clues that it contains or is about arithmetic. Note: this is probably some specific tool, a bit like — or more likely an expansion of — the safety filter. Probably not an LLM itself, but a less sophisticated but more ‘exact’ technique (string pattern search, other specific parsing — if you ask ChatGPT what that is, will tell you actually it uses such basic techniques, but it is unclear if this is true of course)
- If ‘arithmetic’ has been detected in your prompt, another prompt is generated asking an LLM to produce python code, which the (a different?) LLM delivers
- This python code is executed in a separate environment
- The result is returned and is added to you prompt in some way (probably prepended with instructions). Now a call to the GPT4 LLM is made to generate the actual reply (the continuation) we were looking for
- The chat interface adds that little clickable element and its expansion with the code execution it got earlier, to the output.
During 2–3 you see a temporary “Analyzing…” element.
Which means that ChatGPT is effectively prompt engineering under the hood, using multiple calls to (the) LLM(s) behind it, and using a hidden ‘plugin’ to execute python code. By the way: remember plugins? They were introduced in beta almost a year ago with Wolfram the poster child of the plugin idea. It’s somewhat forgotten now (the current form being ‘Custom GPTs’ as something for end users to use, but under water OpenAI and Microsoft are using the architecture with their own plugins here. What used to be ‘plugins’ is now mostly ‘actions’ inside the ‘build your own GPTs’ setup). I’ve called the safety filter approach “AoD-filters” in my talk, where AoD stands for ‘Admission of Defeat’: the admission that you cannot approximate the required level of understanding — required for safety — by approximation through next-token-prediction. This is more of that. It is inspired engineering, but it is also a sign that improving the LLM itself is not the route OpenAI/Microsoft believes/invests in. Money has to be made.
There is a separate ‘supersize-me’ effect that plays a role here: context sizes. Growing parameter sets even larger might have been a dead end as of a year ago with the launch of GPT4, growing the context size (the amount of prompt the decoder can pay attention to) was another avenue, which now has been realised (and possibly exhausted). GPT4-Turbo as a context size of a whopping 128k, which is extremely large compared to a year ago and before, and this enables putting a lot in in-context-learning / prompt engineering under the hood. Which is now being exploited to the hilt.
Google “engineers the hell out of LLMs”
Google on the other hand, seems to still be focused on the LLM itself as well. One trick that Google pulled with Gemini is really interesting, and to be honest, I did not get it at first, I drew a wrong conclusion, now fixed in the post that described it. In that post I drew your attention to this element of Google’s reporting on beating GPT4 on benchmarks:

This little element labeled “CoT32“. ‘CoT’ we can recognise as Chain-of-Thought, the widespread prompt engineering technique to tell an LLM to generate step by step answers. Prompt engineering, of course, is our intelligence working around the limitations of the LLM’s ‘next-token-prediction’ mechanism that is — I repeat — all it does, just on a massive scale, thus enabling it to approximate other behaviours, with more or less success (depending on domain and prompt).
But digging into the technical paper tells you what it really stands for (and I missed that originally, because they were comparing it to 5-shot by GPT4 — see the article for what that means regarding lies, big lies, statistics, benchmarks). What it actually stands for is that the LLM doesn’t do a single generation, it does a whopping 32(!) of them, all with the “step-by-step” instruction added to the prompt. And then it tries to choose the best answer from the 32 generated replies (‘continuations’). The mechanism of choosing the best one is technically interesting, but we do not really know all the details that go into this — these are engineers tinkering to get optimal results, after all — but we can guess how it approximately will work. The most interesting tidbit was that each token that is generated will get a ‘confidence’ result, say a combination of how high its score was and how close other alternatives were. In an example: if it is clear that token ‘auc’ is the only next token really, the confidence in that token will be high. But if two tokens — say ‘and’ and ‘.’ — are roughly equally likely, the confidence at that point (and thus for the whole result) will be lower.
Of course, when you look a bit from afar, you see a simple pattern: no improvement on the fundamental capabilities of LLMs, but instead running them many times over with the same prompt and trying to do something with a collection of answers. The problem is: if I need to run generation 32 times to get a, say, 3% performance gain, that looks like getting closer to light speed: ever more energy required for less improvement. That seems not really sustainable. And it is another sign that LLMs are not improving in any fundamental way.
Creating multiple LLMs based on the same training material
Another approach I came across somewhere (can’t bother to try to find it again as I think it will not scale) was the idea that instead of using one LLM, one could use, say, 8 ‘variable instances’ of that LLM. Now, digital technology being what it is, the exact same LLM will give you the same result on the same prompt, except for the basic randomness that is built in at the moment of next-token selection. CoT@32 makes use of that builtin randomness during generation to have 32 runs of the same parameter set produce 32 different all these runs use the exact same parameter set.
Training a model is — as my talk explained — a huge search task: you are searching for an optimised set of parameters based on minimising the errors that are made on the training material. But training starts with initially random values for all those parameters, which means that when you train a model again with exactly the same training material, the search task will find a different optimum (parameter set), thus giving you in effect a different model. That opens up a strategy to create multiple different models based on exactly the same training material, and then somehow let them all generate a reply after which — a bit like with CoT@32, but harder — you could try to use all results to select or create a definite one.
I suspect this is not really cost-effective (training a model like GPT4 is truly expensive), but it is another example of engineering around the limitations of the LLM-approach itself. (By the way, the talk contains some information on these ‘optima’, which are — unsurprisingly — not always ‘optimal’).
Conclusions and Consequences
In short: while things apparently get better on the chatbot front, there is no fundamental improvement on current underlying LLM-technique driving this, and not one in sight either. Instead what we see is
- ‘engineering the hell out of’ the current approach to LLM (like CoT@32, or even combining having multiple models, which doesn’t seem sustainable as a way forward)
- ‘engineering the hell out of the surroundings of the LLM, which seems to be an ‘Admission of Defeat’ for LLMs. Google will be doing the same with their chatbot.
I like ‘engineering the hell out of it’, I do. I wrote in praise of Meta’s Cicero more than a year ago, remember? But both Google and OpenAI/Microsoft are actually suggesting to us that the approach “massive next-token-generation in order to approximate understanding” — also known as trying to approximate meaning by making a statistical analysis of the ink distribution on a page of meaningful text (with thanks to Frederik van Eeden who came up with that comparison in one of his essays more than a hundred years ago)— is a dead end (and their engineers probably know it, even if their marketing people will never admit it).
LLM development saw a disruptive change with Transformers in 2017, it has scaled in parameter volume (see below) until roughly a year ago, but enough that becoming larger apparently doesn’t really help much. Now the context (prompt) size has been massively expanded (GPT4: 128k) which opens up a lot of ‘prompt engineering’ under the hood, something that is now actively exploited by the players. The attention (pun intended) is switching from parameters to contexts/prompts. But we should not forget ‘prompt engineering’ is in fact a technique that compensates for LLM limitations (on ‘understanding’), which means that the massive switch to contexts/prompts is a de facto admission that LLMs themselves are a dead ends, understanding-wise, that are destined to become just ‘dumb-creative’ elements in a wider landscape of technologies that make up chatbots and friends.
PS. Parameter volume instead of parameter size
I propose we do not talk about parameter size or number of parameters, as some models are shrinking the size of parameters (Gemini Ultra even uses 8-bit integer ones, i.e. simple bytes) probably in order to be able to use many more. Here too, quantity has its own quality: it may be better to mostly have a train load of imprecise parameters than a smaller set of more precise ones. To compensate for such optimisation choices, I suggest we should not talk about the number of parameters anymore, but the volume of parameters (number times average size). Just so we can actually compare. These choices too, by the way, are part of engineering the hell out of it.
This article is part of the The “ChatGPT and Friends” Collection
[You do not have my permission to use any content on this site for training a Generative AI (or any comparable use), unless you can guarantee your system never misrepresents my content and provides a proper reference (URL) to the original in its output. If you want to use it in any other way, you need my explicit permission]

7 comments