Enough discussing proposed fixes and improvements for ArchiMate (here, here, here, here and here). Time for a ‘normal’ modelling post. This time about the concept of virtual data. Most of you will know what a virtual machine is, so what is virtual data?
A virtual machine is something that looks like hardware, but isn’t. It’s software pretending to be hardware to other software. It is one of the many forms of a platform, a useful concept, by the way, e.g. when thinking about application rationalisation.
So, what is ‘virtual data’? How can data be virtual? Here is a scenario. Suppose we have an Oracle database. I can address the data in the database as tables which I can address using SQL code. These data tables are stored on permanent storage (disk) somehow.
Those tables, if I want to model them are Artefacts that are Composite children of the overall database Artefact, like in this view where a Data Warehouse is modelled:

For those new to this blog: I am using the column-oriented colouring Mastering ArchiMate colouring scheme as it stresses one of the strong points in ArchiMate: the difference between subject, behaviour and object.
Anyway, next to data that is stored in a certain way on disks, the database also has the possibility to have virtual tables. These tables are not stored on disk, but they are generated on-the-fly from other data by the database system. The application accessing the database does not see the difference, just like the fact that an operating systems has no knowledge that it is running on virtual hardware instead of physical hardware. This is a pattern we are seeing more and more as big data becomes more popular and software logic is creeping into what used to be passive data.
The question is, how do we model this virtual data in ArchiMate? ArchiMate, after all has a rather fundamental idea about data: it is passive. Which in this case it really isn’t as we are being fooled by logic that we are accessing stored data that resides somewhere. We’ll get to that later. So, the first attempt might look like this:
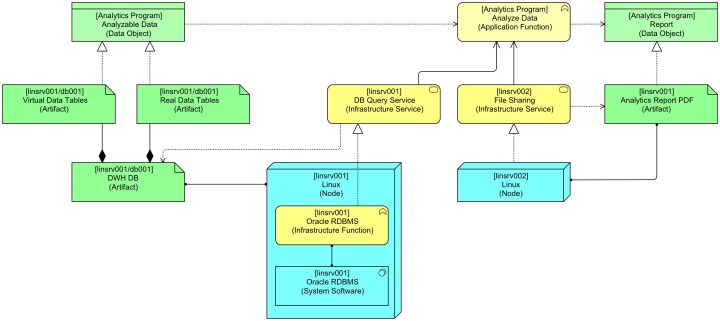
Here we see a more complete picture, including the application that makes use of the database. We’ve modelled another Artefact to represent this virtual data. It’s an Artefact (Virtual Data Tables) that doesn’t exist, or fleetingly at most and only while the SQL query is being processed. This, by the way, is not that different from web applications where part of the application is generated on the fly by the web server (the HTML/javascript code that is sent to the browser for execution there). See this older post or the discussion on modelling web browser based systems in Mastering ArchiMate.
From the application’s perspective, there is no difference between the physical data and the virtual, on-the-fly generated, data.
Suppose now that we have some performance issues in our DWH. Performance is always a matter of behaviour being to slow, and having a good map of your landscape can help you look for the potential troublemakers quickly. In the Mastering ArchiMate colouring scheme, these are all the yellow-ish elements.
But the image above doesn’t show the behaviour that creates the virtual tables explicitly. The overall database element is not much help here. We bought that system, but we built the virtual tables ourselves and this software does not show up.
Let’s add our virtual tables as behaviour:
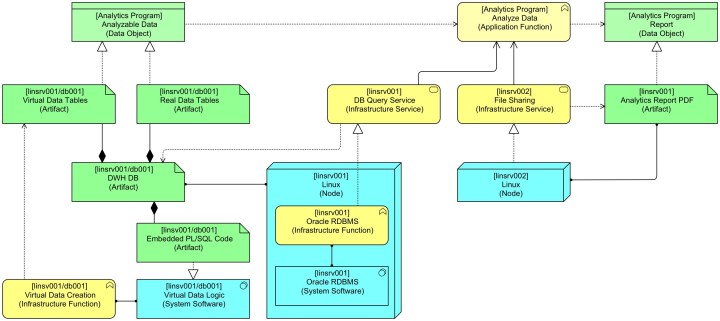
As our virtual data is being generated by PL/SQL code we’ve written in an Oracle database, the code shows up as embedded code as part of our database. As this is code that runs in the database, we’ve chosen to model it as System Software with its own behaviour that generates those on-the-fly, temporary, virtual tables. Now, we immediately see that there is more behaviour than just the application. We might want to inspect the PL/SQL code to see if it is the cause of the performance issues.
One thing bothers me, though. Just because it is PL/SQL code that runs in a database platform, doesn’t make that code ‘system’ software. It’s not a platform, it’s application code. It’s in fact part of our application, it’s just a part that is technically running in a different way.
So, we may decide we want to model this PL/SQL code as an Application Component, not as System Software. We can do that like this:
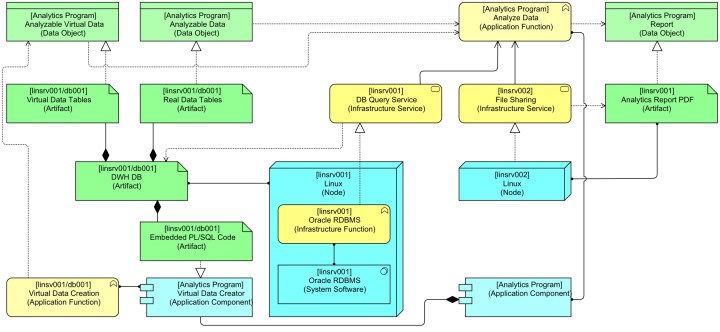
I’ve also added an Application Component for the Analytics Program here to make clear that both behaviours are part of the same application.
There are some other options, still. For instance, we might choose not to model the Artefact that represents the on-the-fly generated (virtual) data:
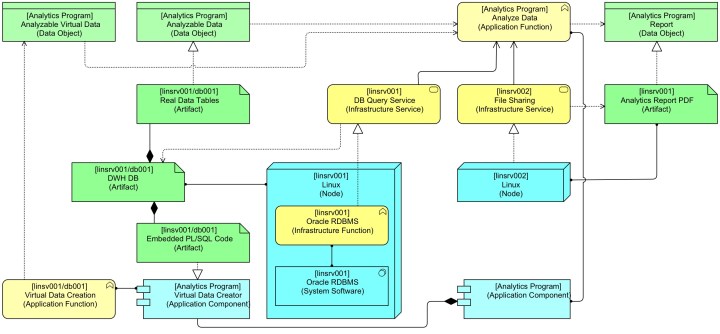
This is my chosen solution, but it also has a disadvantage: it breaks a common pattern of ArchiMate modelling: application data (Data Object) is normally realised by infrastructure (an Artefact). We might bring back this realisation. The following picture shows a way (in black) and one (the red one) that is not allowed in ArchiMate:
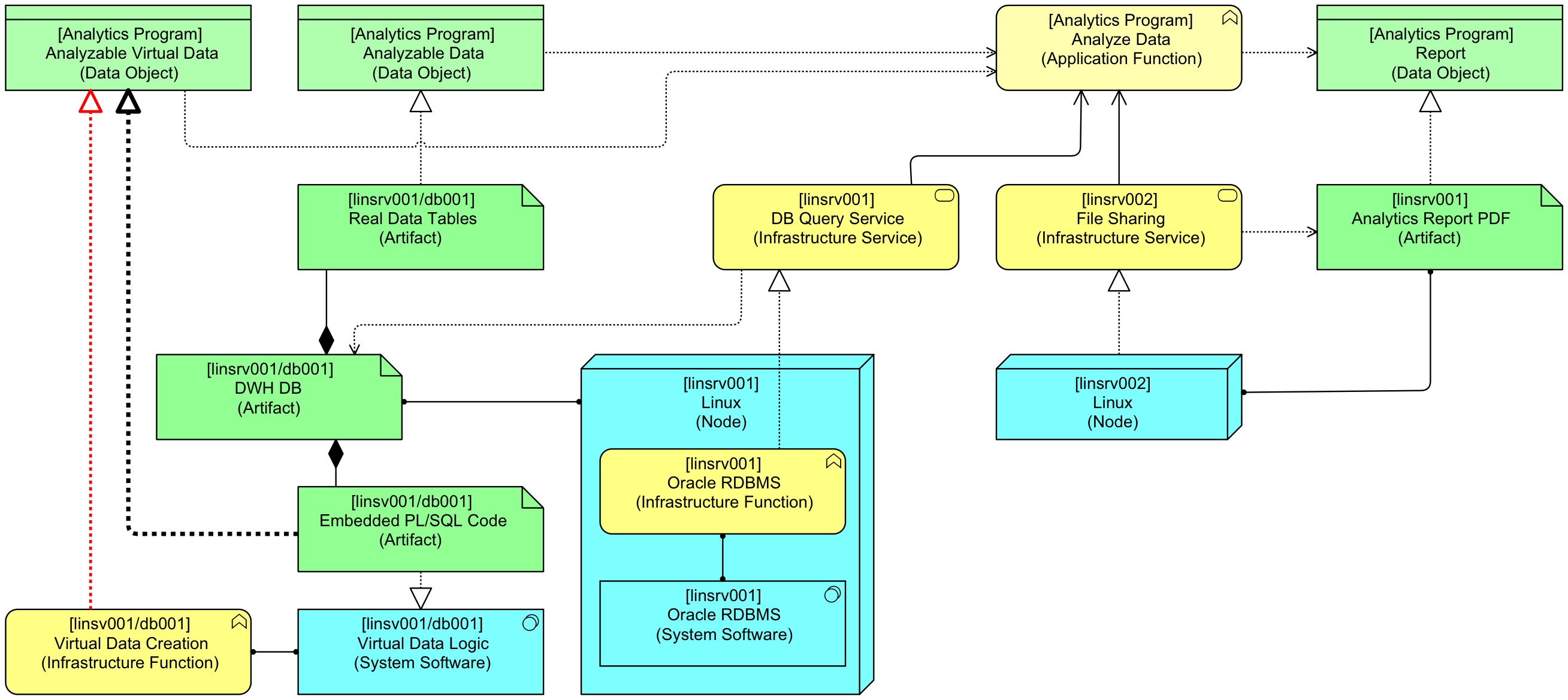
Though the “Embedded PL/SQL Code” Artefact now Realises the “Analysable Virtual Data” Data Object we would lose the route via System Software and Infrastructure Function and that would mean that we’re back in a situation that the behaviour is hidden/invisible again.
The red Realisation drawn in the picture above would do the trick, but it’s not part of ArchiMate. To have real support for Virtual Data somehow behaviour would have to be able to Realise a Data Object. That could be the case if the strength of the Access and Realisation relation would switch. I haven’t thought that one completely through (this is work in progress because I’m currently working on sorts of data management / data analytics subjects). Intuitively, though, I would think that it would be cleaner if ArchiMate would only use Realisation as an abstraction relation between layers (infra, application, business — and frankly maybe that should become platform, application, business, the ‘infra’ moniker is somewhat ‘previous century’ if you ask me).
ArchiMate being what it is now, the one but last picture shows my chosen pattern. In general terms: modelling everything that is business specific code as Application Components and Application Functions has served me well and this pattern design choice can be extended to the concept ‘virtual data’.
