A while back, I wrote in the blog post ArchiMate is overrated (and underrated) that using ArchiMate doesn’t really have that much added value for communicating simple, high-level views to stakeholders (users, management), but its structure does bring advantages that enables us to model large (detailed) landscapes. Such models have an essential advantage when they are modelled not just graphically, but in a real ArchiMate modelling environment: it opens the Business-IT landscape for useful analysis. But, to be practically able to do analysis, there are limits to our freedom of modelling.
Analysis in ArchiMate models is probably always ‘dependency analysis’. On which applications does this business process depend? What infrastructure supports this critical application? How are certain requirements, such as those from risk and security realised? Such insight is highly valued in organisations, given the fact that in complex landscapes, this lack of insight results in uncertainty and risk. Comparing enterprise architecture to a game of chess (something I regularly do, see Chess and the Art of Enterprise Architecture): if much of the situation on the enterprise chess board is hidden from you, it becomes more difficult to make good moves.
There are two possible models of analysis of a model. One is ‘by hand’. A human looks at the model and investigates, walking through the model to investigate dependencies. You pick an element in a view and you ask the model “what is attached to this element?” and so you build up an answer to a question you have.
Because humans are intelligent, and can interpret models as they go along, this option works in minimal circumstances. If the modellers did not use fixed patterns, and they actually understood ArchiMate enough to use the correct relations, you can get an answer to your question.
But such manual analysis is slow and expensive, and — as humans are not machines — error-prone. The ideal situation therefore is to have automatic analysis, generally called `reports’. To create reports from models, such as the answers to “give me all applications that support this critical process for which the regulator has just announced new requirements” you need a model that can support analysis, and just using the syntax of ArchiMate is not enough.
The first step to take is that you need to model with fixed patterns. That has to do with the type of algorithms these reports actually are. If you follow the patterns in the Mastering ArchiMate book (which have been designed to enable both integration of the model with other models next to analysis), a business process using an application looks like this:
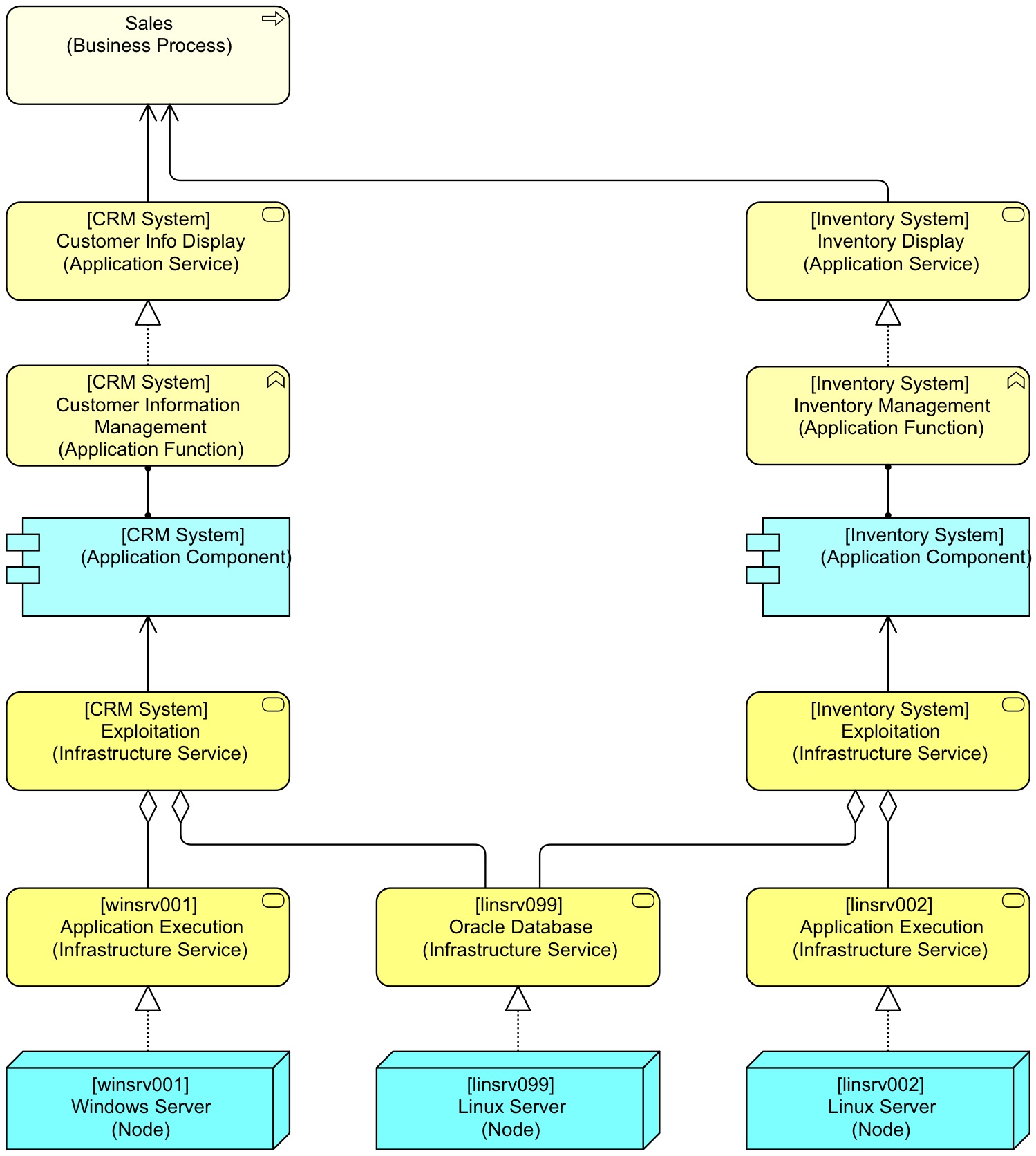 In this simple example, there is a process supported by two applications, which in turn are supported by three servers. If we want to create a report which servers support which process, we need to execute the following algorithm in pseudocode:
In this simple example, there is a process supported by two applications, which in turn are supported by three servers. If we want to create a report which servers support which process, we need to execute the following algorithm in pseudocode:
For every business process (A) in our model
Print "A uses"
For every application service (B) that is used-by (A)
For every application function (C) that realises (B)
For every application component (D) that is assigned-to (C)
For every infrastructure service (E) that is used-by (D)
For every infrastructure service (F) that is aggregated by (E)
For every node (G) that realises (F)
Print " F"
And for the above ‘model’, the result would be:
Sales (Business Process) uses [winsrv001] Windows Server (Node) [linsrv099] Linux Server (Node) [linsrv002] Linux Server (Node) [linsrv099] Linux Server (Node)
Apparently, we need some more intelligence in our algorithm, as node linsrv099 is mentioned twice. And we could output this as tables, or in any other form. Now, suppose one of our architects has modelled the inventory system and did it with a smaller number of elements? So, the model becomes:
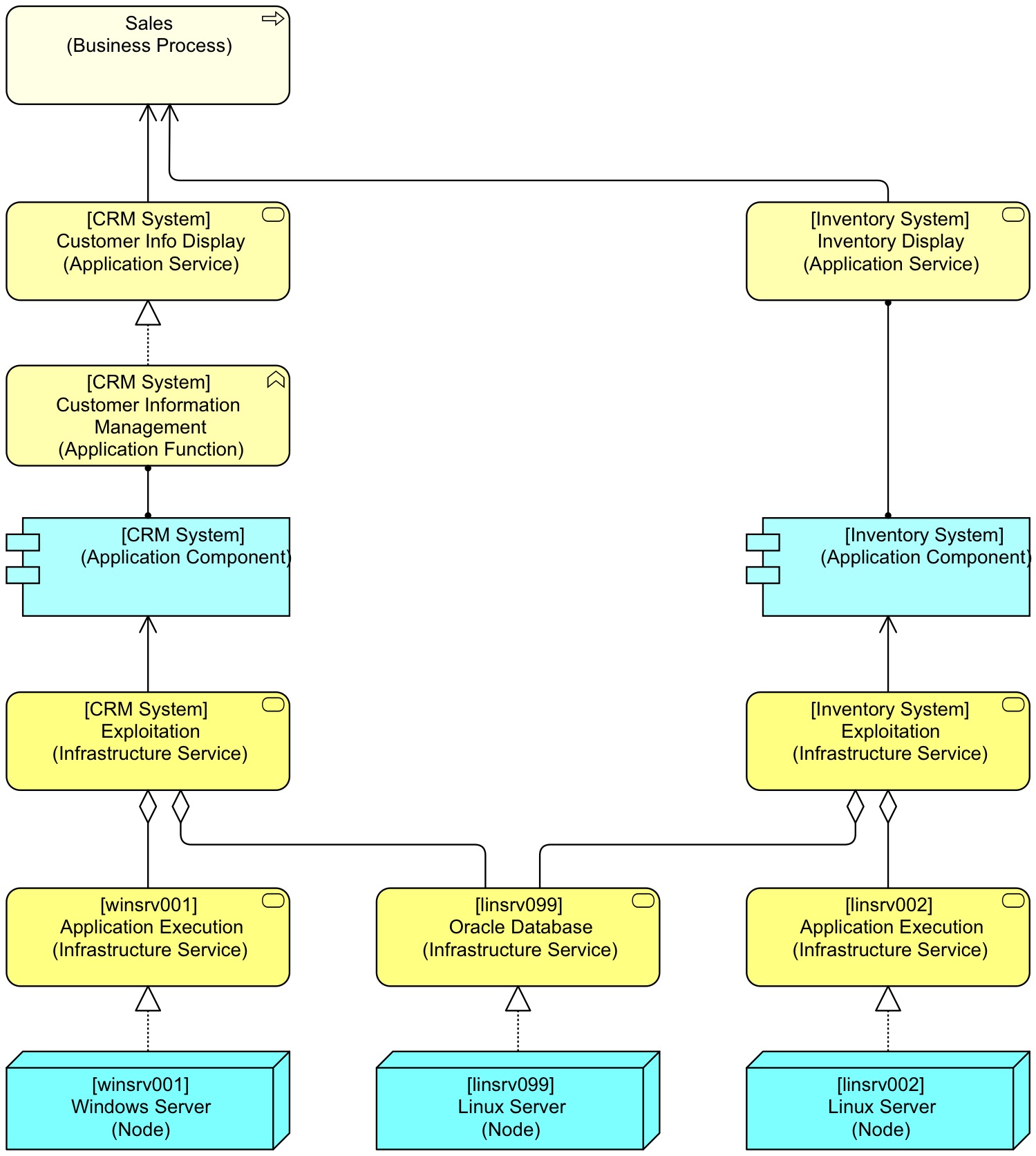
There is nothing syntactically or semantically wrong with the right hand side. This is the choice you as a modeller have. But now, the output of our algorithm will become:
Sales (Business Process) uses [winsrv001] Windows Server (Node) [linsrv099] Linux Server (Node)
— which is wrong because linsrv002 is missing — unless our algorithm becomes:
For every business process (A) in our model
Print "A uses"
For every application service (B) that is used-by (A)
For every application function (C) that realises (B)
For every application component (D) that is assigned-to (C)
For every infrastructure service (E) that is used-by (D)
For every infrastructure service (F) that is aggregated by (E)
For every node (G) that realises (F)
Print " F"
For every application component (D) that is assigned-to (B)
For every infrastructure service (E) that is used-by (D)
For every infrastructure service (F) that is aggregated by (E)
For every node (G) that realises (F)
Print " F"
What you see here is a fundamental tradeoff in modelling: for every variation in patterns you get in your model, your analysis will get more complicated with an extra route to follow. This is why it pays to have as little as variation as possible in your modelling patterns, that is, if you want to use your model for reporting. And it is also important that your different patterns do not complicate analysis routes. So, for instance, you might Assign a Role to a Business Process when it performs the process, but when you want to model the process owner as well, you do not use assign-to again, but use Association so you have different patterns for different meanings.

The left hand side is ambiguous under analysis, we might want to follow the route from function to the performer, but not to the owner. Using a different relation, makes automated analysis possible (shown at the right hand side). This option is not always available, but can be used. Note: this example is not the best as ArchiMate s quite clear that Assign-To means ‘performs’ and not ‘owns’. See also Section 12 Secondary and Tertiary Architecture in the book. But for instance, we Associate the application manager with the Application Function and the application owner with the Application Service. If we would not have the application function and we would Associate both with the Application Service, we would be unable to tell application owner and application managers apart. This is one of the reasons to have that extra element, the Application Function, in our models.
You can also work with properties of elements and relations, but that is not easily visible nor easily usable in ad hoc analysis, so I prefer actual structure above properties. And the one thing I never use for discrimination in analysis is the textual label. The label is unstructured information and not to be used for analysis.
What can you conclude from this? Two things:
- When you choose your modelling patterns, you need to think about the (unknown) future.
- If you change your pattern, you need to update the entire model before you go on adding to it.
When recently management wanted to know which outside services (SaaS, data services, etc) we were using, the business unit with the good model was able to answer that in less than 10 minutes. The ones without a decent model took ages, many hours of expensive work time and produced a rather incomplete list. And that happens again and again. It is an investment that pays, but only if it is done well:
The false start
When organisations start out with modelling in ArchiMate, they tend to try to keep things as simple as possible. Don’t make a too complex model, it is difficult to maintain, communicate and so forth. So, they look for the minimum of modelling (often only graphically oriented, not structurally oriented). Why add that Application Function and Application Service, can’t we just use Application Components? Such an approach could come up with a model that can perfectly answer our question about processes and servers and that has the following structure:
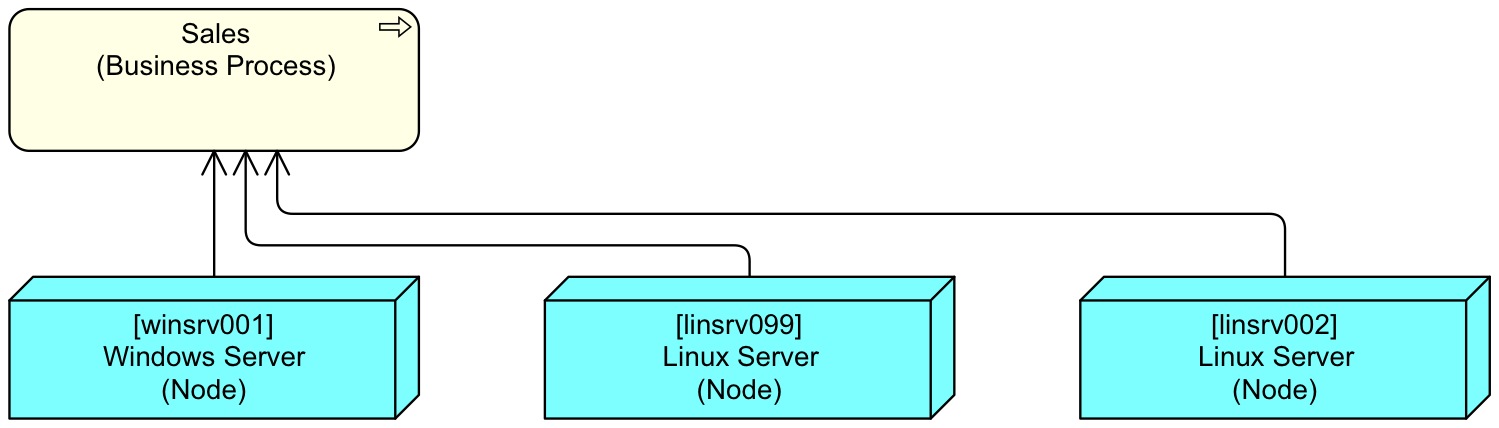 The problem of course is that such a model can answer only one question. The power of a good model is that it can be used to answer many questions, including many that haven’t been asked yet. Designing that is hard. Luckily, using it is pretty easy. And you hardly ever communicate the views of the model itself to the stakeholders. But the reports are easy to understand and very valuable. And even with an extensive detailed setup as in the first diagram above, the simple report can be generated. Visually, if must be, in the form of the last diagram. Basically: leaving detail out when you are reporting is possible, ‘inventing’ it is not.
The problem of course is that such a model can answer only one question. The power of a good model is that it can be used to answer many questions, including many that haven’t been asked yet. Designing that is hard. Luckily, using it is pretty easy. And you hardly ever communicate the views of the model itself to the stakeholders. But the reports are easy to understand and very valuable. And even with an extensive detailed setup as in the first diagram above, the simple report can be generated. Visually, if must be, in the form of the last diagram. Basically: leaving detail out when you are reporting is possible, ‘inventing’ it is not.
Blimey! I did not digress!

Slight digression on that topic: I very often see imperative programming and from time to time graph based languages (e.g. Cypher for Neo4j), But one should not forget declarative programming, and in particular logic programming like prolog. I used to work on a kind of impact analysis engine for ArchiMate and I were able to walk through relations (and particularly derived ones) in less than 10 lines of code.
LikeLike
I am also interested in analyzing Archimate with the help of declarative programming. Could you, please, share some information about it? How queries to the model designed?
LikeLike
Well, that depends of course on the tool you use. Some tools (such as BiZZdesign Architect and its successor BiZZdesign Enterprise Studio, or Sparx Enterprise Architect) come with embedded languages that can access the model and produce all kinds of output. I only have experience with BiZZdesign’s embedded language. Here is a snippet with a function that finds all objects without relations. Sorry, formatting gets lost in the comment.
// Show objects without relations, sorted by views where they appear
// If object has label "Child active", it has no relation itself, but it has children with relations
// If object has label "Child(ren) inactive", it has children, but it nor its children have a relation
// If object has neither label, it is childless
function show( obj) {
if ( (obj is AbstractElement || obj is AbstractCompound)) {
rels = obj.relations();
refs = obj.references();
if ( rels.size() == 0 ) {
views = Set();
forall ref in refs {
views.add( ref.parent("AbstractView") );
}
if (obj.children().size() == 0) {
// Object has no children
output views, obj.name(), obj.type(), obj.parentPath();
return false; // obj has no relations nor children (with relations)
}
else {
childrenHaveRelations = false;
forall child in obj.children() {
childrenHaveRelations = childrenHaveRelations || show( child);
}
if (childrenHaveRelations) {
output views, "Child active: " + obj.name(), obj.type(), obj.parentPath();
}
else {
output views, "Child(ren) inactive: " + obj.name(), obj.type(), obj.parentPath();
}
return childrenHaveRelations; // obj has relations because it has children with relations
}
}
else {
return true; // obj itself has relations
}
}
return false; // obj is irrelevant and counts as object without relations
}
LikeLike