Large, complex landscapes are a pain. With hundreds of servers, hundreds of applications, thousands of users (and thus usage patterns) and a constant flux of small and large changes, few organisations are really in full control of what they actually deploy. Now, in the Chess Game from Hell that Enterprise Architecture is, not knowing your position when you make a move is already a problem. But Enterprise Architecture only reflects the problem this is for the entire organisation.
Many attempts have been made to solve this problem by trying to set up reliable documentation of the Current State or As-Is. Most have failed. Keeping up to date with a changing landscape is difficult, it seems to require an inhuman discipline for the organisation. And large models with all the aspects (either documented in specialised tools, in a ‘stretched’ CMDB or — shudder — large drawings without any model structure) turned out to be rather unusable for many. Everybody got lost in them. So, the results were difficult to use and difficult to keep up to date. No wonder the initiatives failed.
We can safely ignore unstructured documentations, such as large sets of diagrams created in some graphical tool such as Visio. They are unmaintainable. For large complex landscapes only structured documentation, i.e. a model, will do. Such a model is not by definition maintained in an official modelling tool. A CMDB (Configuration Management Database) with so-called CIs (Configuration Items) is in fact also a structured model. The structured information in a help desk system (to let the help desk attach tickets to the right application or service is also a structured model. The tool employed by risk management that contains information about processes, applications and their problems is also a model.
The single model problem
One of the basic problems is the way people tried to document the Current State: in a single administration/model. As I argued in Mastering ArchiMate, a single model of the organisation cannot work. The meaning of each model for the organisation lies hidden in its use, and as many uses may contradict each other, a single model is out of the question. How can uses contradict each other, you may ask. In a practical example: suppose we want to be able to know what infrastructure is required for an operationally critical business function, we might need something like this when modelling the use of a complex application in ArchiMate (where arrow directions generally signify dependency, so the Management Reporting Business Function relies on the servers and not the other way around):
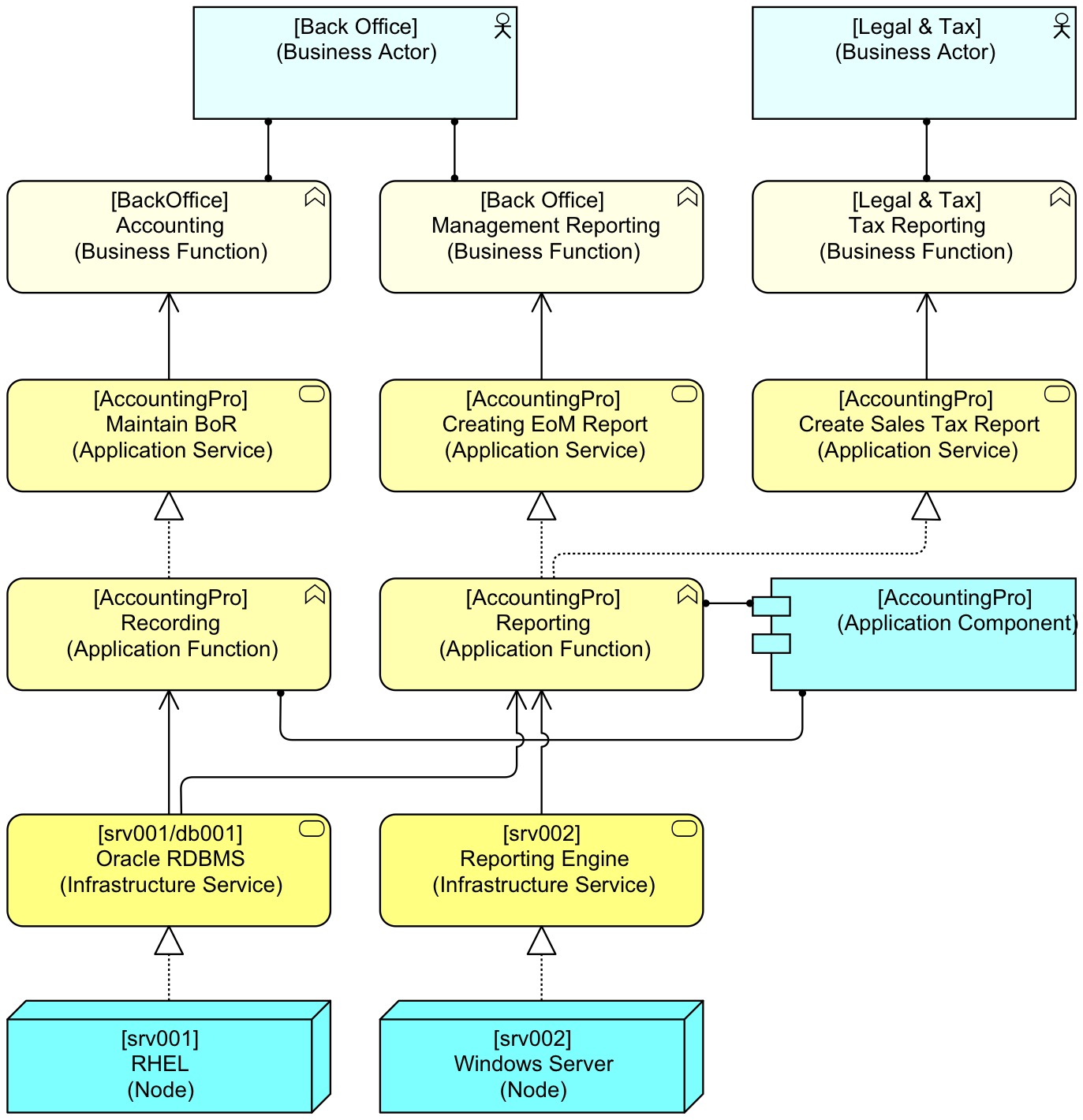
With a structure like this, it is clear that the critical Operations process does not rely on the reporting infrastructure, so Server srv002 does not require high availability, whereas srv001 does. Many more analyses, useful for architects can be made from models like these.
But when the user reports a problem with an application to the help desk, the help desk doesn’t want to log the incident on a specific application service, they will both get lost in all the arcane details of the above view. Often even the user does not know which part of the application he or she is using, or even the official name of the process they are performing. So, the user wants to say “application X is slow” and all incidents on Application X get logged against a single CI. For them, the detailed structure above is unusable, even if it is correct. So, the help desk requires something more simple, like (again ArchiMate):
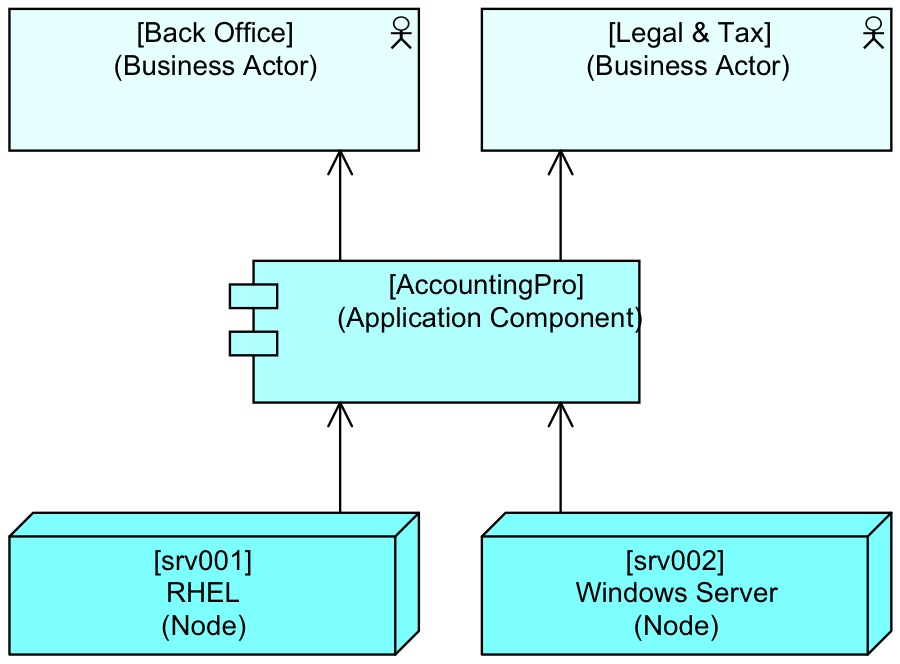
You can of course add more details to the model of the help desk, but depending on the tool’s ability to shield the users from irrelevant details, you might make it much more complicated for the users. Generally there is a golden rule: only provide people with information that they can practically use (or request information that they can practically provide). And the corollary is: you will not be able to support all the documentation needs of the organisation with a single model. And a corollary of that is: if you want prevent a chaos of incoherent documentations, you need to set up a coherent set of them.
Back to Reality
When we do want to be in control of our landscape, we need to be able to ascertain that the landscape we have conforms to the requirements we have set for it. E.g., if we have defined a couple of standard operating systems (to improve the cost structure of the IT organisation), say Windows and RHEL, we would like to know if our landscape contains many exceptions. What use is it to have a standard, if you can’t tell that you are actually complying? The ideal situation is of course if this would be automated in some way, a form of automatic discovery or forced compliance. We’ll get back to that below, but for the moment most landscapes don’t have that possibility.
In many organisations, the situation is like this (click for larger picture):
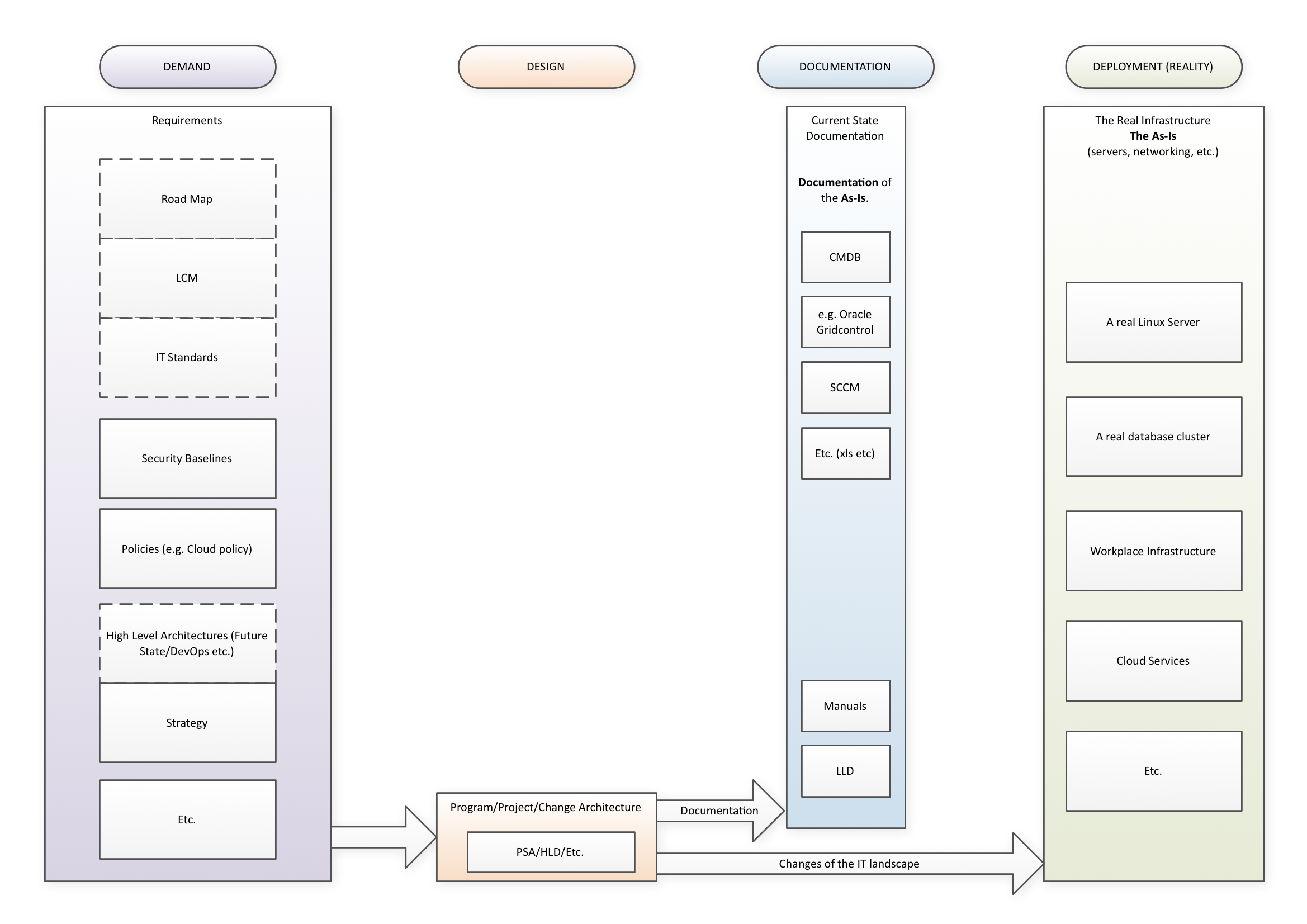 On the right, in green, the reality is represented. On the left, in purple, the documentation of all our requirements is shown. We have many softer and harder requirements. We may have security baselines, road maps, IT standards, high level goals in architecture (such as DevOps or Exception-Based Architecture) et cetera. Then, change happens, either smaller changes or larger projects. Changes also produce documentation, generally about the to-be. Project (Start) Architecture, High Level Designs and towards the end, Low Level Designs, Installation and Maintenance Manuals, etc. There is also a lot of documentation about the As-Is, though it is seldom a coherent set. We may have a CMDB, we may have distribution tools which distribute software and have information about what is distributed. We may even have tooling that documents the situation live, as for instance Oracle Gridcontrol does (now, of course called Oracle Cloudcontrol, our marketing message must go with the flow after all). The quality of these documentations is generally not extremely high. Keeping it up to date makes the IT organisation sluggish and bureaucratic, not something customers like.
On the right, in green, the reality is represented. On the left, in purple, the documentation of all our requirements is shown. We have many softer and harder requirements. We may have security baselines, road maps, IT standards, high level goals in architecture (such as DevOps or Exception-Based Architecture) et cetera. Then, change happens, either smaller changes or larger projects. Changes also produce documentation, generally about the to-be. Project (Start) Architecture, High Level Designs and towards the end, Low Level Designs, Installation and Maintenance Manuals, etc. There is also a lot of documentation about the As-Is, though it is seldom a coherent set. We may have a CMDB, we may have distribution tools which distribute software and have information about what is distributed. We may even have tooling that documents the situation live, as for instance Oracle Gridcontrol does (now, of course called Oracle Cloudcontrol, our marketing message must go with the flow after all). The quality of these documentations is generally not extremely high. Keeping it up to date makes the IT organisation sluggish and bureaucratic, not something customers like.
From left to right, the model of ‘documenting reality’ has Demand, Design, Documentation and Deployment, hence I call it the D4-model.
Now what happens in this situation when you want to establish if your deployed reality (green, on the right) conforms to your demand, your requirements (purple, on the left)? You get the following situation (click for larger picture):
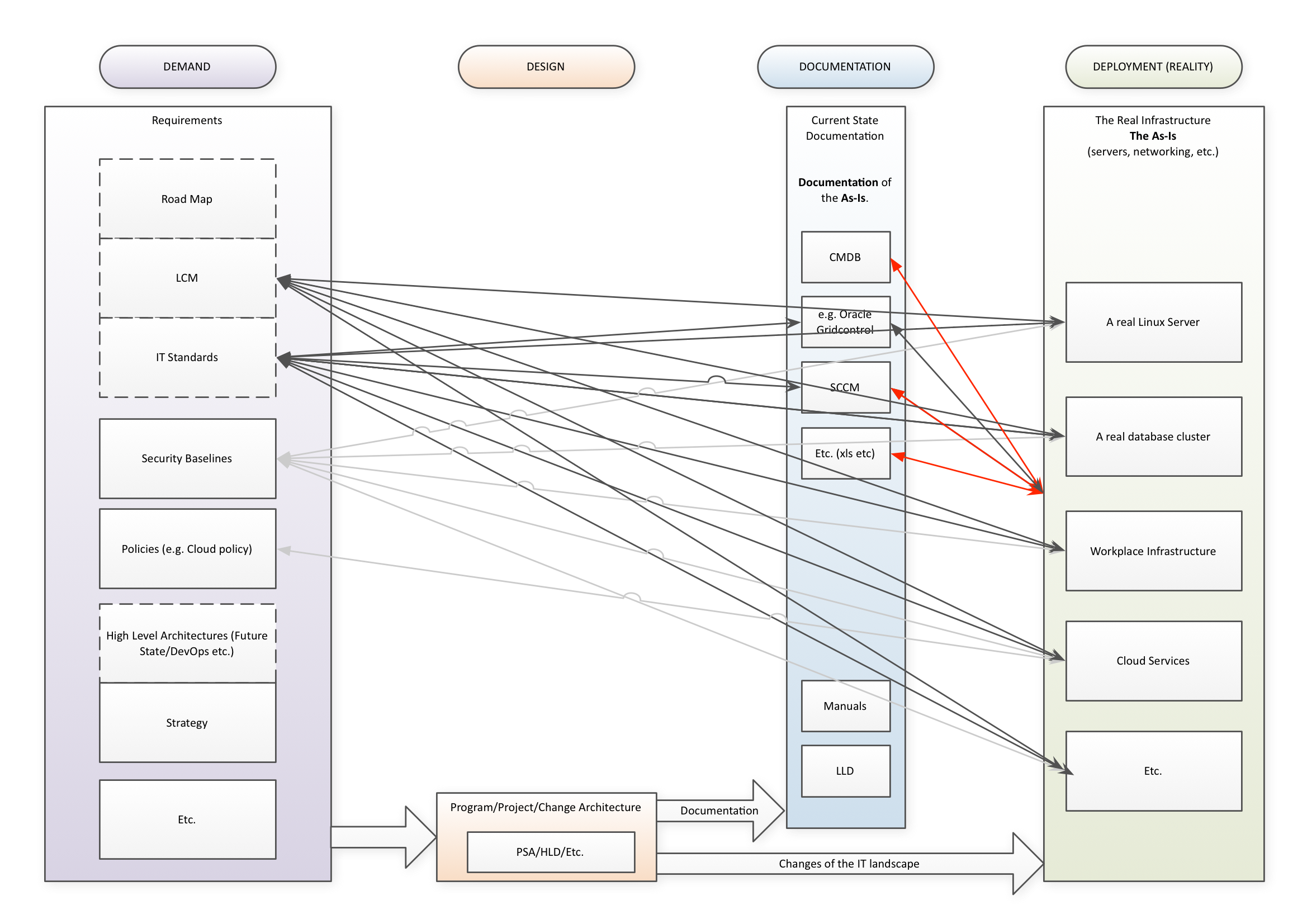 You end up with an unmanageable many-to-many connection between the requirements on the one hand and reality on the other. And the act of checking itself is a disaster. Who wants to log in on every server to check if its contents conform to the set of requirements? Ideally, you want to check the documentation of reality, but unless that documentation is a reliable representation of reality, that is an untrustworthy approach. For something like Oracle Gridcontrol, you may say that it is a reliable source of reality. But who makes sure that that standard server that has been deployed using automated deployment tools hasn’t been changed by hand by some engineer because of some problem? Yes, I know our standard says the Java version must be 7.4.1.13.12.b8-whatever, but how do I know some engineer in reaction to application problems hasn’t changed that after we deployed it? So, in general, we cannot trust the red relations in the picture above.
You end up with an unmanageable many-to-many connection between the requirements on the one hand and reality on the other. And the act of checking itself is a disaster. Who wants to log in on every server to check if its contents conform to the set of requirements? Ideally, you want to check the documentation of reality, but unless that documentation is a reliable representation of reality, that is an untrustworthy approach. For something like Oracle Gridcontrol, you may say that it is a reliable source of reality. But who makes sure that that standard server that has been deployed using automated deployment tools hasn’t been changed by hand by some engineer because of some problem? Yes, I know our standard says the Java version must be 7.4.1.13.12.b8-whatever, but how do I know some engineer in reaction to application problems hasn’t changed that after we deployed it? So, in general, we cannot trust the red relations in the picture above.
What would an ideal picture be like? Well, being able to check your landscape for compliancy with requirements requires two things:
- A reliable documentation of your landscape that allows for checking
- A usable mapping of requirements to ‘what must be checked’
I think the mature setup looks like this (click for larger picture):
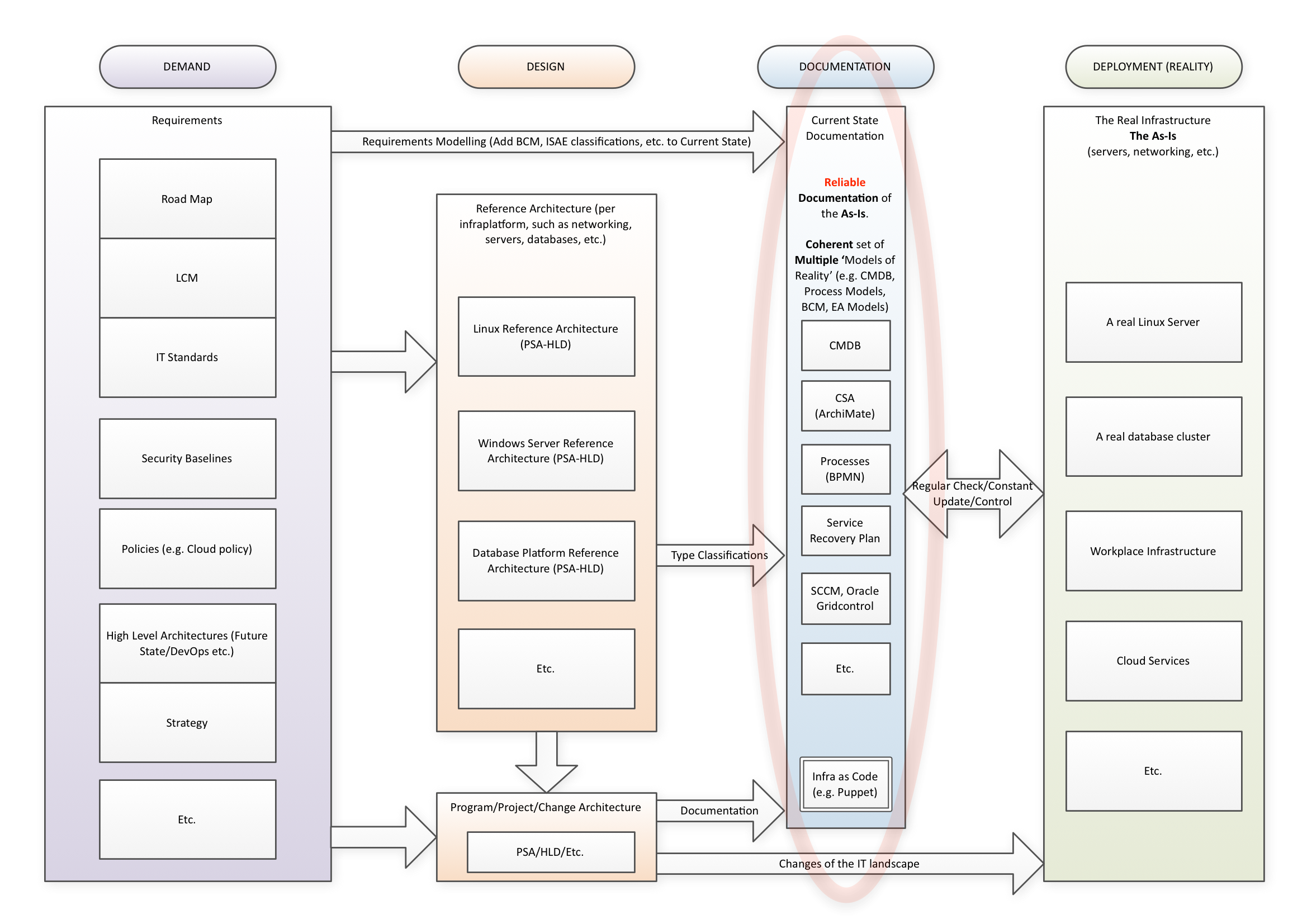
We have to make or ‘set of coherent documentations’ reliable and usable to become the instrument of checking, to be in control. Ideally that means a lot of automated discovery and/or a very good governance surrounding changes where documenting the change in a structured sense is essential. We have to set up a good set of reference designs for what should be in our landscape so we don’t have to check everything against everything. The to-be-checked requirements (most of them coming from the reference designs) must also end up in our documentation. We will then be able to set up a useful check between the two within the documentation. For this, the documentation used for checking must:
- Be structured as to allow algorithmic checking. An ArchiMate model in a tool with a decent scripting/programming language is a good option, as ArchiMate is a both structured and versatile modelling language. And the ArchiMate views don’t have to be communicated with non-architects at all.
- Contain both a reliable representation of the As-Is as well as a good representation of the requirements that are important for checking. For instance, a large As-Is model may also contain a ‘standard’ Java 7.4.1.13.12.b8-whatever element and all Java’s in your landscape must be recognisable withe respect to version and type by being aggregated to that abstract element. You must have a reliable association between the two in the model, so that you can easily find those that are non-standard. This, by the way, is doable.
In my experience, setting up these kinds of structure and processes is difficult, mostly because you have impact across the entire organisation. But maintaining and using it is relatively simple.
Infrastructure as Code
Finally, documenting your As-Is must of course be as automated as possible. The whole solution does not scale in effort if there is too much hand work involved. So, setting up automatic reporting from deployment to documentation is key. Many modern IT support systems already have this, they may have installed an Agent on every server they control which can report its real setup.
In the last picture, you see a double lined box in the blue Documentation column. What this represents is the reverse of automatic documentation, it is a combination of automatic deployment and documentation. Instead of documenting a server, you write the setup of a server down as ‘code’. And the software system guarantees that the actual server conforms to this ‘design’. An example of such a configuration management platform is Puppet. Here, the documentation is the server in a certain sense, hence the moniker “infrastructure as code”. With virtualisation of infrastructure, we are seeing more and more setups where infrastructure starts to look like software, where too the actual code is the only real documentation that is reliable. Not quite literate programming, but it might become like that at some time in the future, and we might enjoy infrastructure setups that are as powerful and trustworthy as Donald Knuth‘s code already was in the 1970’s. But maybe that was just the quality of Knuth himself when he created his software.
PS. If you want to discuss my views with me in person: I will be speaking at Gartner’s EA Summit 2015 in London UK on May 20 2015, as well as giving the final keynote at the MBT-Congress in Houten The Netherlands on May 21 2015.
